At DoorDash, dashing is highly process dependent. Dashers require a firm grasp of the end-to-end delivery process to complete orders successfully — and earn money. The first iteration of DoorDash support content did more to explain how to dash, handle common delivery issues and pitfalls, and maximize the dashing experience than subsequent iterations have done.
Our recent effort to revamp the Dasher support hub built a system that allows Dashers to find support answers independently, which reduces support costs. However, the existing resources available to answer common Dasher issues were:
- Hard to find because resources are spread across numerous channels and sources; Dashers must already know exactly where to look if they hope to locate answers, and
- Content sometimes didn’t help resolve a Dasher’s issue, resulting in long calls with a live agent to reach a resolution.
FAQ articles in the revamp needed to be concise and support rapid changes, such as adding screenshots of the app or upcoming guideline changes. Building a system to support this flexibility on each mobile platform would require duplicate development and would also require each native app to be updated when the content structure changes. Native applications can take weeks to roll out whereas web rollouts can be accomplished immediately. So, we decided to build a common web app that can be hosted within the native application to provide an in-app experience while also providing the flexibility to make rapid changes.
Architecture
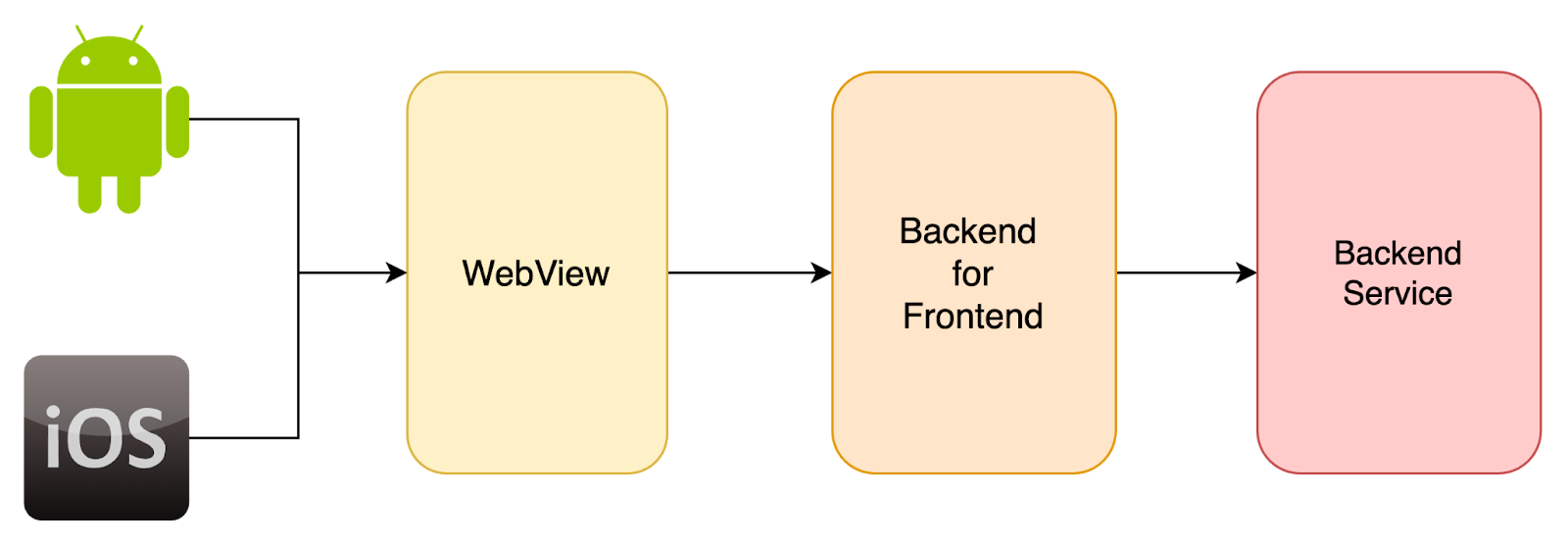
Figure 1: The first iteration of our solution (MVP) followed this architecture: Mobile (iOS/Android) ⇒ WebView ⇒ Backend for Frontend (BFF) ⇒ Backend Service.
As shown in Figure 1 above, both mobile clients use WebView, ensuring the same experience across clients. Some menus like in-app support chat deploy mobile client-specific callbacks to bridge between the native app and web view experience.
The BFF is used to transform the request format from HTTP to gRPC to allow the backend service to parse. The response is similarly transformed from gRPC to HTTP. No business logic is handled at the BFF layer; it exists solely to format the data from the backend service into a format suitable for the web application.
The backend service stores and serves the content. The article contents are stored as a JSON that holds not only the content but also the UI formatting. In MVP, all articles, categories, menus, and snippets are stored as JSON fixtures. Each change in the article requires manually formatting the article, updating the JSON fixture, and deploying the backend service.
MVP scope
To minimize the scope of the MVP, we kept the content localized to the U.S. market. Localized content with language and country/region-specific content would have complicated the initial launch; while we kept these features in mind, we did not implement them in the MVP.
At the start, we kept the content stored in JSON fixtures rather than investing in a full database. The JSON fixtures allowed us to iterate quickly and repeatedly through the data format. A drawback to this: We couldn’t use a more robust search system. Instead, we simplified to use a basic search solely on article titles using Levenshtein distance to account for misspellings. All the tags, categories, menus, and article content shown within the FAQ had to be manually formatted into JSON and uploaded.
Communication protocol
Many messages are sent to enable seamless transitions between the native applications and the FAQ feature running within a WebView. For example, the WebView may need Dasher context or an interaction with the UI may need to navigate back to a native view.
Both Android and iOS have methods to send messages to and from their WebViews. To send messages from the WebView to the native app, the native side must register handlers or use delegation. For example, the native side may register a handler called “WebViewModuleCallbacks.” From the WebView side, this will resolve to a property on the messages window.
// For Android
WebViewModuleCallbacks?.postMessage(...)
// For iOS
webkit?.messageHandlers?.WebViewModuleCallbacks?.postMessage({...})To send messages from the native side to the WebView, JavaScript must be evaluated in the form of a string. For example, on iOS:
WebView.evaluateJavaScript("WebViewModule.completeCall(1234, { payload: \"somePayload\" }")It should be noted that the evaluated JavaScript must reference something that is already available at runtime within the web application. For this reason, a global instance that could respond to messages was implemented for the FAQ feature (i.e. “WebViewModule”).
We faced a few challenges with the following messaging pattern:
- By default, the receiving side of the message does not acknowledge or return a result in response.
- There needed to be a way to manage the complexity of the different message types as feature requirements evolved.
- Features and client versions are constantly changing; a message that may have been introduced will not be available in older application versions.
A pattern based on JavaScript promises was implemented to solve for the first identified challenge. To do this, an instance within the web application maintained a collection of ongoing message promises. These message promises could be referred to at a later point by an identifier. When the web application prepares to send a message to native, it creates a new promise in the collection along with an identifier. The identifier is then passed alongside the message contents from web to native. To complete the message, the native side evaluates JavaScript and passes back the identifier and any results, fulfilling the promise.
To resolve the second challenge, a typed message contract is formed to manage the complexity of handling multiple message types:
export type ScriptMessage = {
name: string
payload?: Record<string, unknown>
}The “ScriptMessage” type carries the name which identifies the message’s intent. This name allows the native and web applications to switch the specific message handling. The message’s receiver should know how to unpack the payload’s contents.
We’re still working to resolve the third challenge — the moving target of client versions — through incremental changes. Considering the promise-based pattern described earlier, if the web application sends a message that is not supported by the native side, it could stall the application while it waits for the promise fulfillment. To prevent this, the native applications currently forward their version in an initial configuration message. The web application maintains known versions of the native clients and compares against them when handling messages.
WebView
To a web engineer, a WebView is simply another application with some embedded protocols that allow for bi-directional communication between the mobile and web layers.
For the WebView tech stack, we leverage DoorDash’s existing frameworks and libraries, which include React, React Query, and our internal design system. We chose to use React query as our data fetcher/state management because it has cache and cache invalidation capabilities out of the box and works well with our BFF through REST (representational state transfer) API calls.
WebView entry and exit points
Our application exposes multiple entry points based on the user’s origin within the Dasher app, such as account settings → WebView pre-filtered content to account FAQs. This helps eliminate the need to look through all of the content. The protocol to deeplink from mobile to WebView looks something like this:
// The entry point will be specified by the callee of the FAQ module
enum EntryPoint {
case dashing
case earnings
/* ... */
}
// Based on the above entry point the filter query param will be populated
webView?.load(
URL(string: "https://<app-base-url>?filter=\(entryPoint.rawValue)")!
)We also use a messaging protocol to minimize an article. That way, when a user decides to navigate the mobile app after viewing article content and playing around with the features, they won’t lose access to the article they were just viewing. The handlers are attached to an icon; upon click, it sends a message to the native mobile client to listen for the event.
Message Handler Definition
const postMessageToNative = (args) => {
if (webViewHost === 'iOS') {
setTimeout(() => {
webkit?.messageHandlers?.webViewModuleCallbacks?.postMessage(args)
}, 0)
} else if (webViewHost === 'Android') {
webViewModuleCallbacks?.postMessage(JSON.stringify(args))
} else {
// Web code: do nothing
}
}Server-driven UI content
To support a more robust content-based system, we added all of our FAQ article content on the backend. We then fetch the data through WebView. This enables us to have a single source of truth and makes updates easier through a configuration tool. Additionally, if we ever decide to expose this app as a standalone web app, we will still have the content.
From this project, we have developed a prototype content configuration tool that creates the article content rather than adding it on the client as a fixture. The complex JSON describes the FAQ article structure. This enables future knowledge base collection expansions without development effort.
Here is a sample of the content structure. The article page’s anatomy is partially server-side driven, partially client-side driven:
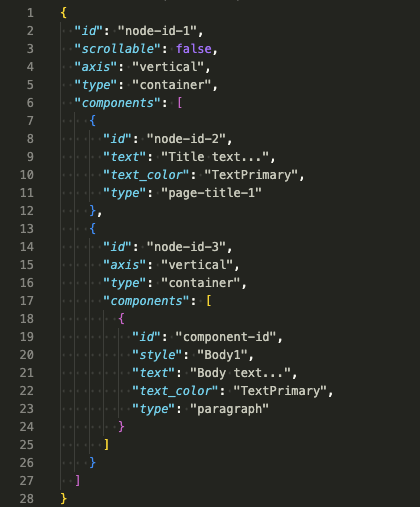

Figure 2: Page layout of an article, partially client side driven, and partially server side driven
This tool allowed us to build a component library that maps the response object into text node components and exports a renderer utility function for the Dasher WebView to consume.
We believe this tool will pay tremendous future dividends when we need to expand the capabilities to other server-driven UI initiatives, such as a screen builder for page layouts.
Development and initial rollout challenges
There are additional challenges in development, debugging, and validation when creating a feature in a native application as presented within a WebView. To understand if something truly works — and if it doesn’t, where it broke — requires knowledge of the native and web stacks.
For example, in developing the FAQ feature there was a defect in the promise-based communication protocol. To debug this properly, we needed to run the web application locally, emit a source map for the transpiled TypeScript, allow and direct the native application to the locally running web application, mark the WebView as inspectable within iOS or Android, and attach to the running WebView from Safari or Chrome. This could be challenging to a lone web developer or native developer, so we often practiced pairing.
Results and future work
There were many noticeable benefits from developing the Dasher support hub as a WebView, notably:
- Quick rollouts: Web deployments are quick and simple, with no friction for user adoption. Mobile app releases, on the other hand, take roughly a week to deploy and around two weeks for meaningful adoption percentages. WebView changes require less than a day.
- Content updates: Because content is stored on the server, it can be updated quickly and often, sending the most recent version to the client without the need for mobile releases.
This also allowed us to create additional projects that will further aid in creating support tools for our customers and agents and will be extended, including:
- Content configuration tool: We can build out this tool further to configure other web flows, reducing development effort to create similar flows in our mobile and web products.
- Component library for server-driven UI content: These components handle rendering the complex JSON, which can also be extended to handle different layouts.
Conclusion / Summary
Creating an improved Dasher support hub in the app was crucial for providing Dashers better access to information. Dashers need clear, concise, and readily available content that provides solutions to problems quickly, without needing to go through live agents. The information also needs to be easily updatable, requiring a unique solution to avoid long deployment times or duplicate work on Android and iOS. Building a common web app allowed us to circumvent the challenges of updating native applications, massively reducing rollout time and giving Dashers access to the most up-to-date information available.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on