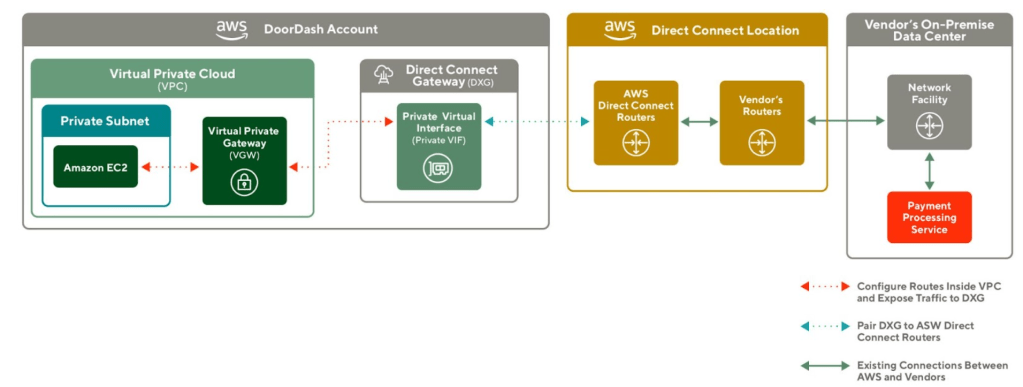
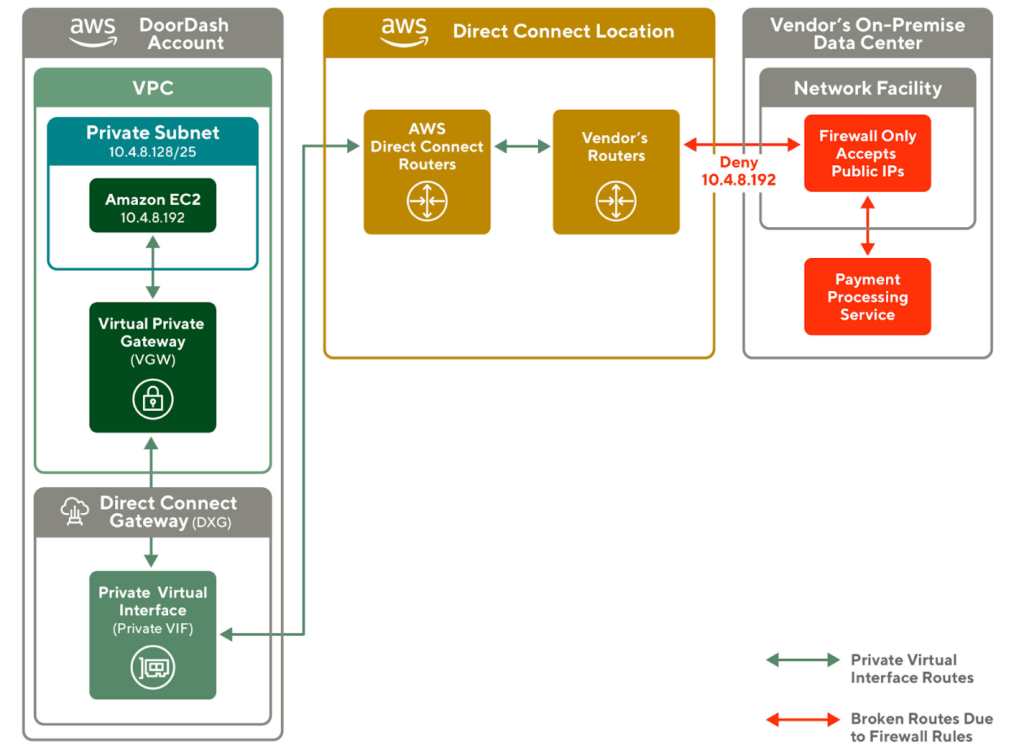
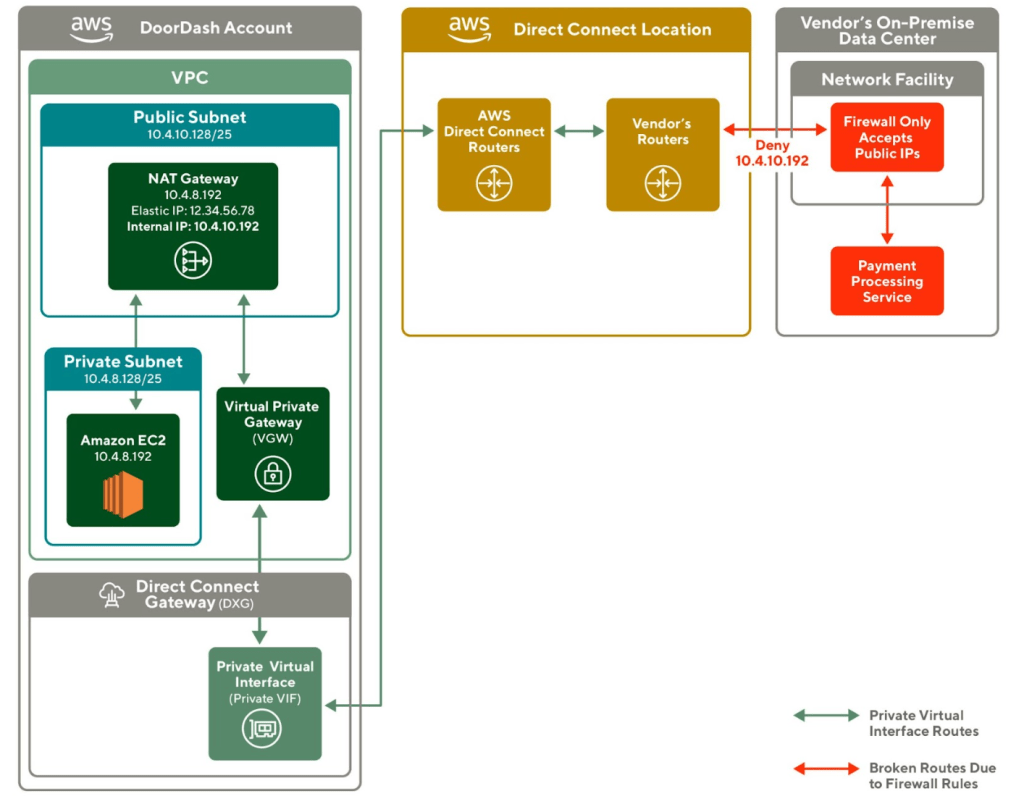
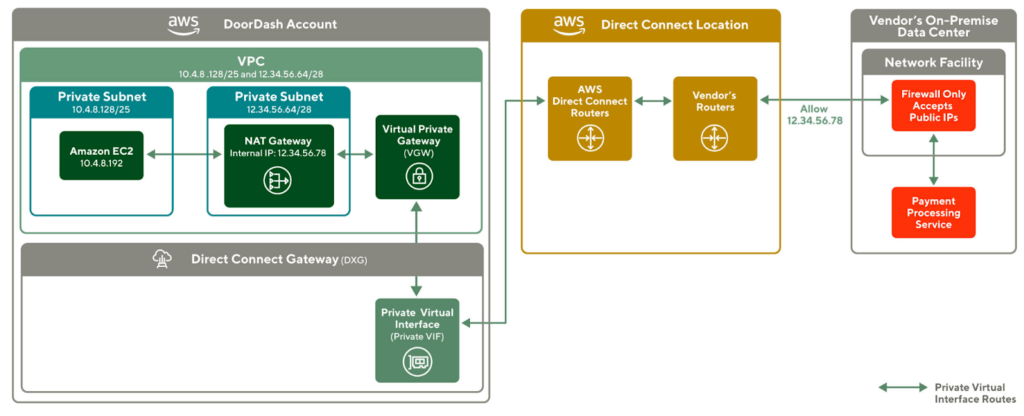
Building software today can require working on the server side and client side, but building isomorphic JavaScript libraries can be a challenge if unaware of some particular issues, which can involve picking the right dependencies and selectively importing them among others.
For context, Isomorphic JavaScript, also known as Universal JavaScript, is JavaScript code that can run in any environment — including Node.js or web browser. The alternative to Isomorphic JavaScript is creating separate, targeted libraries for each environment, for instance one for Node.js and one for the browser. Having a single library across environments offers straightforward benefits — if you can tackle the challenges involved in building one.
Why build isomorphic libraries?
Like many platform teams, the web platform team at DoorDash builds and maintains several libraries aimed at improving front-end developer productivity. Developers at DoorDash write code in multiple JavaScript environments, including React apps and Node.js web services. Furthermore, DoorDash is migrating several pages from being client-side rendered to server-side rendered so the line between which environment code is run in is increasingly blurry. All of these reasons make a strong case that we should make many of our libraries isomorphic because the same logic needs to work in many different environments.
However, there is also additional complexity involved in supporting multiple environments. This complexity is placed on the library’s creator, not its adopter. For some use cases, this trade-off of complexity vs efficiency may not be worth it.
To illustrate some of these additional complexities, we will walk through the process of building a simple fictitious isomorphic library using code snippets and then highlight five specific challenges. Our goal is to provide context that will be helpful in evaluating whether it makes sense to build an upcoming library isomorphically. We also will show some techniques that can be employed to tackle these challenges.
Isomorphic library example functional requirements
Note: The following is written in Typescript, which compiles to JavaScript, so it may include some typing challenges that are not relevant to those written directly in JavaScript.
As mentioned in the previous section, this blog post will dive into how to build a fictitious isomorphic library. To pick a good topic for this fake library, let’s first consider what makes isomorphic libraries challenging, namely having to handle environment-specific cases. Some examples of this challenge may be:
- Relying on any APIs that are native in one environment (for the browser it could be `document.cookies`, `fetch`, etc.) but not native in another
- Having dependencies that are not isomorphic
- Functions that behave differently depending on the environment
- Exposing parameters that are not needed in all environments
Because this blog post focuses on illustrating the challenges of isomorphic JavaScript, our fictitious library has all of these traits. To summarize what we are going to build: a library that exports one function that checks if a coffee order is ready by making a network request and sending a unique id. More specifically, this example has all of the following requirements:
- Exports a single async function named `isCoffeeOrderReady` which optionally takes `deviceId` as a parameter and returns a Boolean
- Sends an http POST request with the request body ‘{deviceId: <deviceId>}’ to a hard-coded endpoint
- Can run in Node.js or browser
- The browser will read the `deviceId` directly from cookies
- Uses keep-alive connections
Now that the details of what this fictitious library will do has been scoped out, let’s dive into the five primary challenges that may be encountered in isomorphic library development, and how to tackle them.
Challenge #1: Choosing the right dependencies
For the sake of illustration, assume that this is Node <=16 and that it doesn’t use any experimental flags. Node 18 has native fetch support.
First we must determine how to make a fetch request. The browser can send a fetch request natively, but to support Node.js, either an isomorphic library or a Node.js library will be used. If an isomorphic library is chosen, it will have to fulfill every environment’s requirements for dependencies. In this case, the chosen library may be scrutinized on its impact on bundle size in the browser.
For simplicity’s sake, we’ll use isomorphic-fetch, which uses node-fetch internally in Node.js and the GitHub fetch polyfill in browsers. The following code illustrates how to make the fetch request:
import fetch from 'isomorphic-fetch'
// Request: { deviceId: '111111' }
// Response: { isCoffeeOrderReady: true }
export const isCoffeeOrderReady = async (deviceId: string): Promise<boolean> => {
const response = await fetch('https://<some-endpoint>.com/<some-path>', {
method: 'POST',
body: JSON.stringify({ deviceId })
})
return (await response.json()).isCoffeeOrderReady
}
Note: For the sake of brevity, many important details such as retry and error handling will be ignored.
Accessing document.cookie
The code at this point ignores many requirements. For instance, in Node.js the parameter `deviceId` will be used as the deviceId that’s sent in the fetch request, but in the browser the `deviceId` should be read directly from a cookie.
To check whether it is in the browser — which means that document.cookie should be defined — see whether the window is defined; `window` always should be defined in the browser and not defined globally in Node. This code snippet looks like:
`typeof window === “undefined”`.
While this is not the only way of detecting whether code is on the server or client, it is a popular way. Many answers in Stack Overflow or in blog posts use this approach.
The full updated code looks like the sample below:
import fetch from 'isomorphic-fetch'
import * as cookie from 'cookie'
export const isCoffeeOrderReady = async (deviceId: string): Promise<boolean> => {
let id = deviceId
if (typeof window !== 'undefined') {
const cookies = cookie.parse(document?.cookie)
id = cookies.deviceId
}
const response = await fetch('https://<some-endpoint>.com/<some-path>', {
method: 'POST',
body: JSON.stringify({ deviceId: id })
})
return (await response.json()).isCoffeeOrderReady
}
While we now are closer to matching the library’s requirements, we have introduced two more challenges to explore…
Challenge #2: Designing a unified API between environments
The previous code change still requires that the `isCoffeeOrderReady` function have a `deviceId` parameter because it is needed in Node.js environments, but the value is ignored in the browser. Instead, the `deviceId` value is read directly from a cookie. The function declaration for both environments should be different — in browsers the function should take no arguments, but in Node it should require one argument — but given that it is isomorphic, it can’t. So the remaining options are:
- The API can be written as shown, requiring `deviceId.` But this action may be misleading to adopters because that value must be passed in the browser, even though it will be ignored; or
- Make `deviceId` optional. This option means that in the browser environment it can be called with no arguments and in the Node environment it can be called with a `deviceId.` However, this also means that the function can be called in Node.js without an argument; Typescript’s static analysis cannot prevent this misuse of the API.
Although the second approach may be the better choice, that fact could weigh against making this library isomorphic, given that the API usage is different between environments.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Challenge #3: Ensuring dependencies only affect intended environments
This `document.cookie` code change also introduced another issue: `cookie` will be installed in Node.js environments despite not being used at all in the Node.js code path. Granted, installing unnecessary dependencies in Node.js is not nearly as detrimental as installing unnecessary dependencies in the browser, given the importance of maintaining a minimal bundle size. However, it is still important to ensure that unnecessary dependencies are not included in a given environment.
One way to fix this issue is to create separate index files for Node.js and browser and use a bundler — for example, webpack — that supports tree shaking. Afterward, make sure that the environment-specific dependencies are only in the necessary code paths. We will show the code needed to do this in the next section.
Using keep-alive connections
Although it may seem straightforward at first to implement keep-alive connections, it is actually challenging. This goes back to our first challenge in choosing the right dependencies. node-fetch does not implement an identical spec as native browser fetch; one place that the specs differ is in keep-alive connections. To use a keep-alive connection in browser fetch, add the flag:
fetch(url, { …, keepalive: true })
In node-fetch, however, create `http` and/or `https` http.Agent instances and pass that as an agent argument to the fetch request as shown here:
const httpAgent = new http.Agent({ keepAlive: true })
const httpsAgent = new https.Agent({ keepAlive: true })
fetch(url, { agent: (url) => {
if (url.protocol === "http:") {
return httpAgent
} else {
return httpsAgent
}
}})
Here the isomorphic-fetch utilizes node-fetch internally but does not expose the agent option. This means that in Node.js environments, keep-alive connections cannot be set up correctly with isomorphic-fetch. Consequently, our next step must be to use the node-fetch and native fetch libraries separately.
In order to use node-fetch and native fetch separately, and keep the environment-specific code path separate, entry points can be used. An example of setting this up in webpack with Typescript looks like this:
package.json
{
"main": "lib/index.js",
"browser": "lib/browser.js",
"typings": "lib/index.d.ts",
...
}
Also note that even though “main” for Node.js and “browser” point to different index files, only one type declaration file can be used. This makes sense given that the goal of an isomorphic library is to expose the same API regardless of the environment.
As a reference, here is a list of some isomorphic javascript libraries that use this pattern specifically for the purposes of having an isomorphic fetch:
The final steps create the Node.js and browser code paths using everything previously discussed. For the sake of simplicity, we will name the files “index.ts” and “browser.ts” to match the files in the example “package.json”, but note that it is a bad practice to include logic inside of an index file.
index.ts
import fetch from 'node-fetch'
import http from 'http'
import https from 'https'
import { SOME_URL } from './constants'
const httpAgent = new http.Agent({ keepAlive: true })
const httpsAgent = new https.Agent({ keepAlive: true })
type CoffeeOrderResponse = { isCoffeeOrderReady: boolean }
export const isCoffeeOrderReady = async (deviceId?: string): Promise<boolean> => {
if (!deviceId) {
// can throw error, etc. just need to handle undefined deviceId case
return false
}
const response = await fetch(SOME_URL, {
method: 'POST',
agent: (url: URL) => {
if (url.protocol === "http:") {
return httpAgent
} else {
return httpsAgent
}
},
body: JSON.stringify({ deviceId })
})
const json = await response.json() as CoffeeOrderResponse
return json.isCoffeeOrderReady
}
browser.ts
import * as cookie from 'cookie'
import { SOME_URL } from './constants'
export const isCoffeeOrderReady = async (deviceId?: string): Promise<boolean> => {
let id = deviceId
// still keep this check in for safety
if (typeof window !== 'undefined') {
const cookies = cookie.parse(document?.cookie)
id = cookies.deviceId
}
const response = await fetch(SOME_URL, {
method: 'POST',
keepalive: true,
body: JSON.stringify({ deviceId: id })
})
return (await response.json()).isCoffeeOrderReady
}
With the creation of these files, all of the library’s functional requirements are complete. In this particular library, there is little shared code, so isomorphism’s benefits aren’t showcased. But it is easy to imagine how larger projects would share plenty of code between environments. It is also important to be certain that everything exported has the exact same API because only one list of type declaration files will be published.
Challenge #4: Testing every environment
Now that the library is completed, it is time to add testing. Most tests will need to be written twice to make sure that everything functions correctly in each environment. Isomorphism couples logic across all environments, changes in one environment now must be tested in every environment. There can be additional challenges in testing isomorphic libraries in realistic scenarios. For example, Jest only has experimental support for ESM.
Challenge #5: Observability — metrics and logging
The final thing to consider is metrics, logging, and other pieces of observability. Infrastructure for observability looks very different in each environment. In this example, the library in Node.js may be extended to capture all sorts of metrics, including latency of request, error rate, and circuit breakers, as well as log warnings and errors with context to help trace across microservices. But in the browser, the library may be expanded to only capture errors. These differences can be resolved by using some of the same problem-solving patterns presented earlier. Nonetheless, it is worth noting this large space where implementations are likely to diverge.
Final thoughts
Several challenges arose in even this very simple, fictitious isomorphic library, including:
- Choosing the right dependencies
- Designing a unified API between environments
- Ensuring dependencies only affect intended environments
- Testing every environment
- Observability — metrics and logging
We also explored whether the benefits of isomorphism are outweighed by some of the compromises and challenges involved. By keeping these challenges in mind as the isomorphic decision is made, it is possible to develop workable solutions.