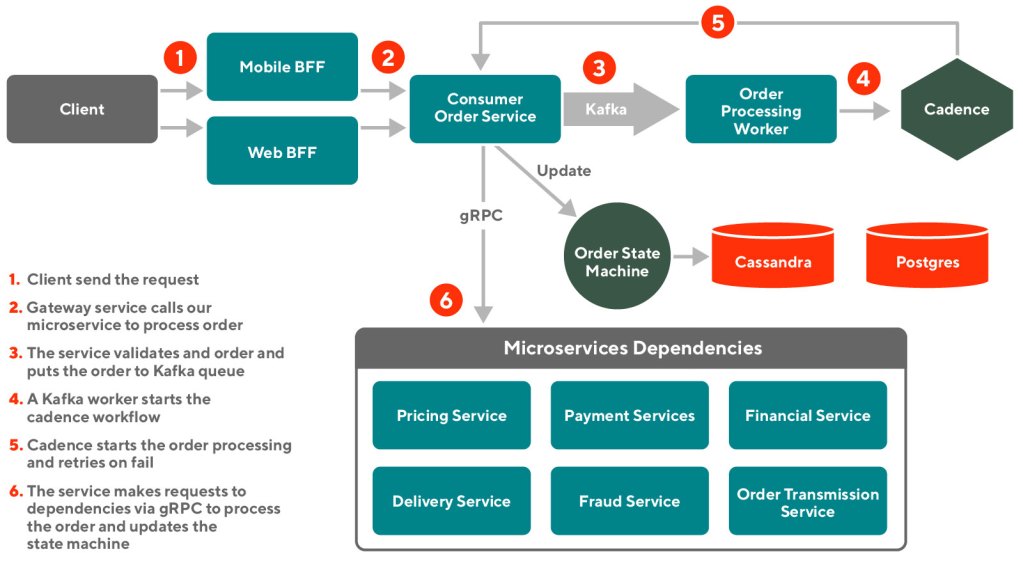
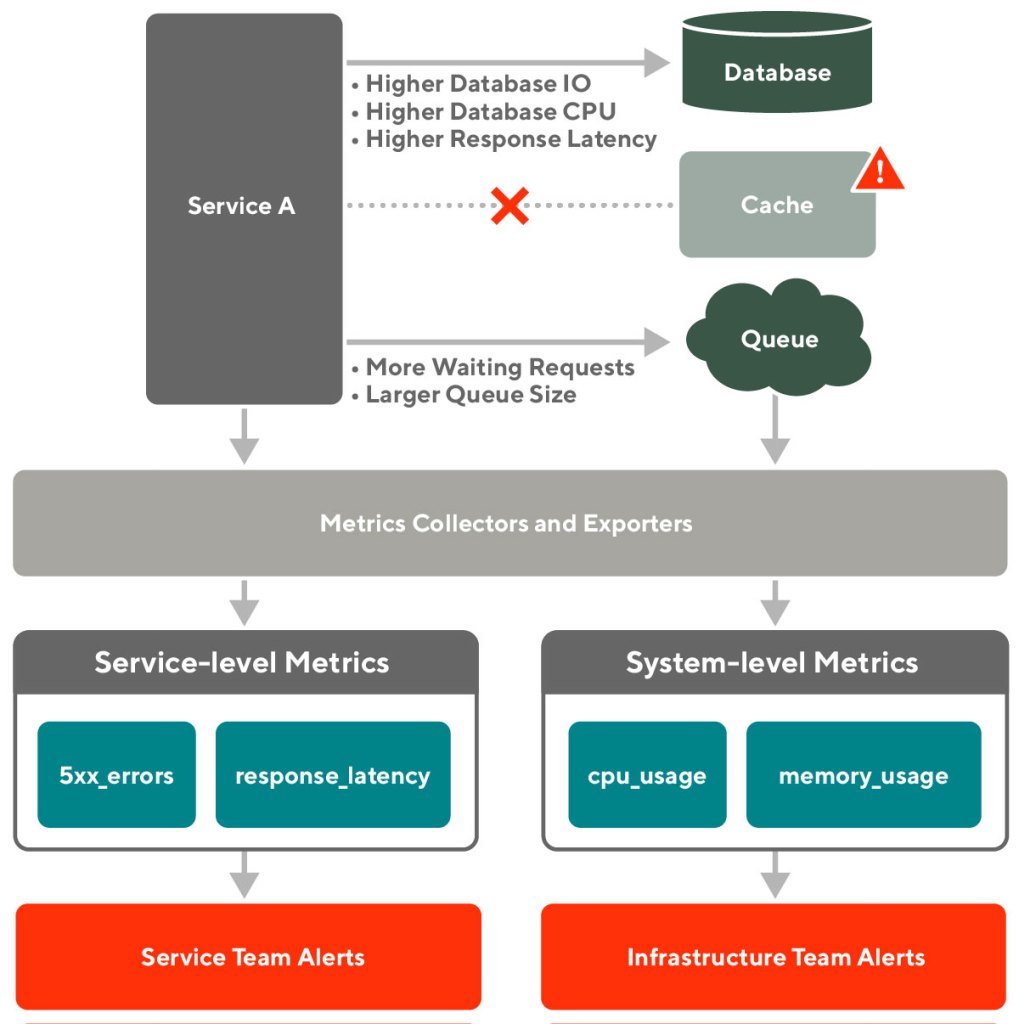
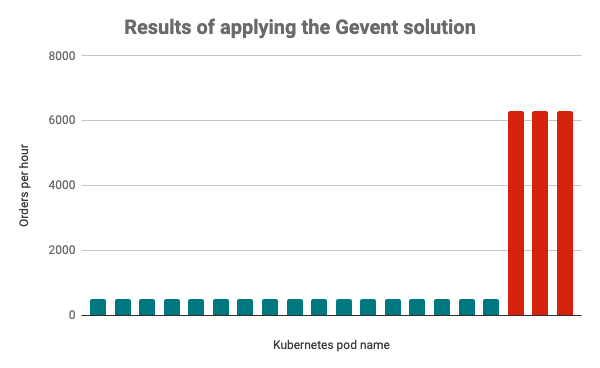
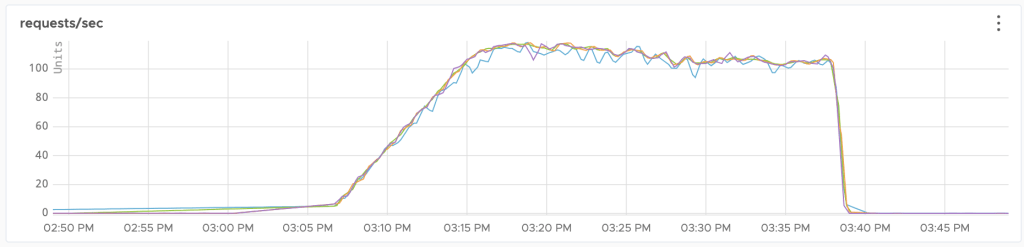
Running experiments on marketing channels involves many challenges, yet at DoorDash, we found a number of ways to optimize our marketing with rigorous testing on our digital ad platforms. While data scientists frequently run experiments, such as A/B tests, on new features, the methodology and results may not seem so clear when applied to digital marketing.
When using digital marketing channels it can be difficult to set up a scientific experiment in a fully transparent manner, which makes it hard to accept testing output without a high degree of skepticism. Specifically, these digital marketing channels have:
- Fundamental limitations for testing tools and infrastructure
- A disconnect between the publisher data and our own internal data
- A lack of control and visibility into the lowest level of detail
Despite these challenges, we found ways of creating rigorous scientific experiments with digital ad platforms. Leveraging the campaign drafts and experiments feature of the Google Adwords platform, we can set up A/B tests. Through these tests, we can determine the incrementality between a new channel bidding algorithm and our existing search engine marketing (SEM) bidding strategy on Google.
This experimentation strategy helps us optimize our marketing budget, by ensuring our campaigns reduce spending while delivering better results.
Challenges of experimenting on digital marketing channels
Digital marketing channels typically have several characteristics that make it hard to conduct the kinds of scientific experiments which would prove the value of optimizations within a single marketing channel, also called intra-channel optimization. In general there are three main issues we’ve seen:
- No A/B testing framework, just pre-post analysis
- No ability to connect upstream data, such as ad spend and impressions, with downstream attribution data (events recorded on the DoorDash side)
- No easy way to get user-level data from the digital marketing channel, even when there are basic needs to understand ad demographics
No A/B testing framework
As the standard for running scientific experiments, we rely on different variants of A/B tests everyday. A/B results, if the experiment is set up correctly, won’t be biased by when the experiment was run, which is the primary limitation with pre-post analysis. Digital marketing campaigns perform differently depending on the seasonality, competitors’ bidding strategy, one-time events, and other external factors that we may not be able to control for. This is even more true for high growth companies like DoorDash, where the business can surge in a relatively short period of time. Since a pre-post analysis will always be biased based on the time of year the experiment was run, we seek A/B tests that run experiment variants concurrently.
No ability to connect upstream data with downstream attribution
Experimentation for digital marketing is all about figuring out the most efficient and effective ways to run marketing campaigns on a digital channel. Tantamount to this understanding is the ability to attribute results to specific campaigns and creatives. Even if we can attribute a single channel to a conversion, we aren’t able to attribute the full conversion journey as it’s not uncommon for a user to see an ad and then engage later on a different platform. Because digital ad platforms provide only click data, we miss possible first-touch attribution from an impression on another platform. Additionally, we cannot easily link data across marketing touchpoints to utilize our own in-house attribution data. Ideally, we’d be able to build a conversion funnel across different touchpoints, which would help link the business results we see to the combination of marketing channels that the consumer uses.
No easy way to get user-level data
Most digital platforms aren’t able to provide user-level data, which means it’s not possible to tell which user or device is assigned to control or treatment groups and views the ads. Additionally, we don’t know how much spend is allocated to that user or device. Instead, the platform can only provide the summarized data at the campaign level. This means that marketers like DoorDash are not able to get the spend, impressions, or final conversions at the user level. These realities of working with digital advertising platforms mean that it’s very hard to understand the entire conversion funnel at the user level.
What the ideal digital marketing testing platform looks like
In a perfect world, marketers who use digital advertising platforms would have full control over the randomization of a customized defined audience, and full access to upstream (spend, impressions, clicks, etc.) and downstream data at the user level. While marketing channels currently provide some of these things, there is no ideal marketing channel that provides such testing platforms yet. For this reason we had to find a marketing platform that would be as close as possible to our experiment requirements so that we could conduct meaningful scientific experiments and improve our marketing performance and budget optimization. After assessing the existing platforms, we found that the Google Adwords Testing Platform was one of the best to facilitate the need.
How Google Adwords permits some scientific experimentation
Google’s paid search testing platform, which is called campaign drafts and experiments, is one of the most advanced testing frameworks available to digital marketers, since it can be configured to set up scientific experiments. Even though it can’t provide spend or impression data at the user level, it does a good job of randomizing users at the auction level, which is the process where Google Search decides which ads will show and their order on the page. Google Adwords also allows marketers to connect the publisher’s click data with their downstream data, to confirm users placed orders. In our case, we want to know if a user clicked a paid search ad then performed any actions on DoorDash’s platform.
Using the draft experiment feature
Let’s take the draft experiment feature and demonstrate how it can be used to set up a scientific experiment comparing our existing bidding strategy with a new algorithm. Google Adwords allows marketers to set up experiments via the draft experiment tool for their search or display campaigns. Google offers step-by-step instructions on how to set up an experiment with this tool. The draft feature enables marketers to test one or multiple variants to a campaign in a scientific way. If the changes make an impact they can be incorporated into the campaign or used for further experimentation.
When we set up the experiment, we can specify how long we’d like it to run, how much of our control campaign’s traffic we’d like it to use, and the budget amount in total for both control and treatment groups. When a potential customer performs a search on Google or a search partner website, either the control or the treatment campaign is randomly activated for the auction, depending on how we’ve split the traffic share between the campaign and the experiment.
Marketers are able to add tracking parameters to each click so as to connect the downstream performance data with the control or treatment groups. This allows marketers to understand the user journey and measure performance of the treatment and control groups. This tracking is very important because it helps us confirm our conversions so as to minimize the gap between data passback issues and post-conversion changes, such as if customers cancel or partially refund their orders, which might impact the test outcome.
Marketers can use the Google testing framework to help improve campaign performance, which includes but is not limited to the:
- Bidding strategy (type or value)
- Creative optimization (ad copy or images)
- Keyword selection
- Audience targeting (demographics)
Creating Google Adwords experiments at DoorDash
In order to spend our marketing budget more optimally, we conducted an A/B experiment to compare the performance between a new bidding algorithm and an existing bidding strategy in DoorDash’s paid search ads on Google. To carry out this experiment, we first identified the key performance metrics we needed to hit in order to be sure that the new bidding algorithm was an improvement. Next, we determined the correct sample size that would yield results that were statistically significant. Lastly, we measured the results to ensure everything was recorded as intended.
Determining success metrics
When determining our success metrics we come up with a target cost-per-acquisition (CPA) that would improve our campaign efficiency at scale. CPA is our north star metric for marketing channel performance, as it best describes the efficiency of our investment. In general, for a mature marketing paid search channel without dramatic structure changes, it is relatively easy to get a cheaper CPA when the budget is low, as the ads acquire customers with high intent quickly. However, it becomes more and more expensive to acquire customers who have lower intent, meaning they need convincing rather than just being pointed in the right direction.
As ad spending increases, it hits diminishing returns at some point with a very high CPA. Therefore, we need to ensure that whatever CPA target we set still performs well at the spend level we need. Since our experiments are not run at scale we need to ensure that the results are not just a factor of smaller sample sizes having more variation. Overall, we are looking to compare the legacy campaign’s CPA with the treatment campaign’s CPA, where both groups have similar spending levels, to determine a winner.

Sample size calculation
An accurate sample size enables us to make a robust inference, and get confidence in our testing outcome. Generally, the sample size for any study depends on the:
- Acceptable significance level
- Statistical power
- Expected effect size
- Standard deviation in the population
Significance level is the probability of our study rejecting null hypothesis. In our case, the null hypothesis states there is no CPA lift between the treatment and control group. While the null hypothesis is assumed to be true, usually we accept a p < 0.05 as the significant level to reject it. Statistical power is another factor that is easily neglected by marketers, it describes the probability of making a correct decision (to reject the null hypothesis) when the null hypothesis is false. We decided to use 80% power, which is common in the industry. In addition, the expected effect size plays an important role and has a negative correlation with sample size. Basically, we would need a large sample size to detect a small lift, while only a small sample size would be needed to detect a large lift. We made an estimation of the expected effect size based on our historical experiments. Finally, the biggest challenge left is to calculate the standard deviation of the CPA that will prove we actually got an improved CPA with 95% confidence intervals.
In general, we can calculate the standard deviation for any metrics if we know the distribution it forms. For example, conversion rates form a binomial distribution, and the number of new conversions, form a normal distribution. With the formula of each distribution we can easily calculate the standard deviation of those metrics. However, CPA is a rate metric which doesn’t form any known distribution, so we are not able to calculate the standard deviation of the campaign’s CPA with any known formula. Therefore, we need some method which can measure the standard deviation in an empirical way given any form of distribution.
The other difficulty we face is the limitation of treating time periods as the experiment units. Experiment unit is the smallest division of the experiment so that two experiment units can receive different treatments. For example, in an experiment that shows two versions of an app to our customers, the experiment unit is each customer who visited the app.
In general, we can treat user ID/device ID/cookie as experiment units, which gives us tons of data points depending on our customer population. However, we can’t use user as our experiment unit since we don’t know how much spend would be allocated to each user. Therefore, we have to use time periods instead, e.g., daily, weekly, or monthly CPA, etc. Since CPA varies by day of week, we tend to use weekly CPA. However, this will dramatically decrease the historical data points we can use.
Assuming we need the historical performance of 100 experiment units for standard deviation calculation, it’s much easier to get 100 consumer data vs 100 weekly spend data in the past, and obviously we can’t wait two years to start our test. In addition, CPA is heavily affected by the spending level (higher spend incurs higher CPA) and seasonality. It turned out that we had very limited weeks that have stable spending and CPA trends prior to when the experiment started.
Based on the two challenges listed above, we need a method that can measure the standard deviation in an empirical way and enlarge our dataset (limited weekly cohorts) at the same time.
Therefore, we decided to go with bootstrapping, which enlarges our dataset using random sampling with replacement. At the same time, bootstrapping’s biggest advantage is that it allows estimation of sample distributions of any statistics (applicable to CPA, which has unknown distribution), and helps calculating standard deviation empirically. Here is the bootstrapping process we implemented to enlarge our data set:
- Step 1: Randomly pick a weekday out of total weekly cohorts
- Step 2: Repeat step one for seven times to formalize a new week
- Step 3: Repeat step two 10,000 times and receive 10,000 new weeks
- Step 4: Measure the standard deviation of those 10,000 weeks
Code for bootstrapping:
```{r}
set.seed(1)
samples_Spend <- c()
samples_Cx <- c()
samples_CPA <- c()
df <- data.frame()
wk <- floor(nrow(df_cx) / 7) - 1 # bootsttrapping 1 less week than the total full week we can get
# Bootstrap & stratified sampling
for (i in 1:10000){ # boostatrpping 10000 times
samples <- df_cx %>%
group_by(wod) %>%
sample_n(wk) # stratified sampling to have each day of week
# statistics for each bootstrap
samples_Spend[i] <- sum(samples$SPEND)
samples_Cx[i] <- sum(samples$CX)
samples_CPA[i] <- sum(samples$SPEND) / sum(samples$CX)
# append result for all bootstraps
df_sample <- data.frame(Spend = samples_Spend,
Cx = samples_Cx,
CPA = samples_CPA)
}
# append result for all periods
df <- rbind(df,df_sample)
```
Now we have all four factors needed. We finalized the sample size and estimated the experiment periods. Let’s start our test!
A/A test:
When setting up a new campaign at Google Adwords, it usually takes days for it to stabilize in terms of spending and CPA. That’s why we set a two week A/A test before monitoring the result. This warm-up period allows campaigns to stabilize and also ensures there is no statistically significant difference between treatment and control group before the test starts.
In Figure 2, below, we can see there is no significant difference between control and test during the A/A test period (Day 10 to Day 34), which means the campaign is stabilized and ready to go.

Monitoring the experiment:
Similar to all other experiments, we should start monitoring as soon as possible to ensure our experiment was set up correctly. In addition to general checks, such as randomization, metrics level, and bucket shares, we also need to ensure that the upstream data aligns with the Adwords UI, and downstream data captures all the conversions from the testing campaigns. More importantly, we need to make sure the spend maintains a similar level across test and control groups, otherwise it is meaningless to compare CPA between test and control groups.
Finally, we leave one to two weeks for a cool-down period after the experiment ends, ensuring we don’t miss any consumers who convert after seeing our ads (lagging effect). The length of the cool-down period is decided based on the attribution model used.
Conclusion
For many data-driven companies, digital ad platforms can be a source of frustration when attempting to conduct scientific experiments to optimize campaign performance and return results. While none of the available digital ad platforms offer the ideal set of tools and insights needed to perform some scientific experiments, it is possible to use what’s there to set up tests with meaningful results. Google Adwords, Facebook, Snapchat and some other publishers do have their own experimentation platforms for marketers to conduct all sorts of tests.
Meanwhile, we demonstrated a real case in DoorDash with the following learnings:
- Define the success metrics. For marketing specifically, no matter if it’s CPA or return on ad spend (ROAS), measure that at the desired spending level.
- Due to the seasonality and marketing fluctuation from markers’ business or the competitors’, utilizing bootstrapping methods can amplify existing data points and calculate the standard deviation empirically.
Acknowledgments
Thanks to Ezra Berger, Wayne Cunningham, Robert Kaspar, Jessica Lachs, and Gunnard Johnson for their careful review of this article. We also thank the cross functional marketing experimentation team that helped us develop the article’s content including Robert Kaspar, Saurabh Basantani, Kate McGrath, Justin Neustadter, Julianna Simon, Josh Li, Kevin Chen, Aman Dhesi.
Photo by Joshua Sortino on Unsplash