Focusing on delivery allowed DoorDash to build a food search engine, but expanding beyond food with more SKUs and merchants requires a substantial upgrade. As DoorDash expands into new verticals such as groceries, convenience, alcohol, and pet food, new challenges arise that our food-driven legacy search wasn’t built to handle.
As our business has grown, our data layer has become more granular, requiring tracking of discrete SKUs for every item offered rather than the nested menus we started with in food delivery. With our expansion into the convenience and grocery space, we need to index new verticals in our search database.
Simultaneously, our system needed to accommodate entirely new product domains. That requires us to bootstrap data labels for new domains, such as grocery, alcohol, and pet food. The vast number of new SKUs creates scaling challenges for our data labeling. As a result of expanding query and document understanding, the relevance ranking of search results also needs to be substantially improved. These new challenges required onboarding machine learning-based approaches.
To solve these challenges, we needed to update our search infrastructure to handle the additional scale as well as to rank new search results appropriately with novel improvements including learning-to-rank and query-and-document-understanding features.
We rebuilt our search infrastructure to support this new scale in search, including the indexing, retrieval, and storage engine. We significantly shortened the time to refresh the search index with a technique we call active/nextgen indexing. We also rebuilt search to conduct federated search to intermix search results across such verticals as food, groceries, and alcohol. Finally, we demonstrated the value of new search storage engines for future search infrastructure improvements at DoorDash.
To extend query-and-document-understanding beyond food, we worked on new taxonomies that help us to understand new types of data in the search corpus in a sensible and structured way. We then shared our experience with machine learning labeling services through human annotations to show how we bootstrapped our new taxonomies. Ultimately, we discussed how natural language processing can contribute to future search query understanding improvements at DoorDash.
We built learning-to-rank systems to make our search results more relevant and expanded our backend systems to define search evaluation and establish a framework to assess whether a result is “relevant” to the query. We showed how we successfully applied pointwise ranking and personalization to make search results relevant. To go into more depth such as going beyond pointwise ranking with new models (such as pairwise ranking), we plan to create future blog posts dedicated to areas such as machine learning applications in search by corresponding DSML teams.
Rebuilding search infrastructure for new challenges
We need to rebuild our search infrastructure from scratch to achieve our central mission of updating our search experience to handle scale and new verticals. This involves:
- Improving indexing speed through Active/nextgen indexing
- Retrieving from multiple verticals at the same time through Federated search
- Having an efficient and flexible search storage engine
Implementing active/nextgen indexing
The first goal for our new search infra was to improve indexing speeds. Because there is a never-ending flow of new SKUs and merchants constantly update their information, indexing speed determines whether customers can get fresh and consistent search results. Earlier last year, we published a blog on search indexing in which we illustrated an architecture that allowed us to build search indexes faster, as shown here in Figure 1.

Building on top of the existing system, the search platform team significantly enhanced the architecture of the next-gen indexing system, as shown in Figure 2.

The new storage system creates a materialized view of search documents before inserting them into indexes. This facilitates even faster index rebuilds and also deterministic and reproducible indexing. The new system also features improved QoS – quality of service – for different types of document updates. For high priority updates whose staleness has a bigger user impact, we chose incremental indexing. This greatly reduces the head-of-line blocking effect during index rebuilds. We also created the ability to switch between old/new indexes with an automated control plane. This significantly reduces human errors, while the state-machine design in the controller makes it possible to reason about the state of the system by, for instance, showing which index is active.
Now that we have updated our search indexing to be at the right speed, we can move our attention to federated search, an architecture that allows us to retrieve search results efficiently and effectively across verticals such as food, groceries, and alcohol.
Building a federated search
Federated search is the dual part of active/nextgen indexing. With this new design, we can retrieve search results efficiently and effectively across verticals through searching each type of data independently and then mixing results from them together to form the final results, as shown in Figure 3 below.

Our previous system was tightly coupled with food delivery systems. As our previous engineering blog illustrated, we were primarily running a search engine for restaurants. The search team spent a significant amount of effort rearchitecting a federated search system to support many new verticals by design. Similar to other companies building their own search systems, we also adopted the federate-then-blend paradigm.
With the new system, onboarding a vertical no longer requires surgical code changes in core search systems. This greatly improves go-to-market velocity for new verticals. Additionally, the modularized nature of the new system allows each vertical to customize relevance according to their business. This makes it possible for discrete verticals at different stages of business development (e.g. enter the market, growing user base, optimizing revenue, etc.) to pivot their business goals easily, for example to consider transaction volume vs. revenue.
The new system also allows us to set latency SLAs on every vertical; when there are production issues with certain indexes, we can achieve graceful degradation without incurring a global outage. For example, if one vertical is having issues the overall search does not need to error out. The blending stage performs global coordination among business verticals. This allows us to do many interesting things such as multi-objective optimization, exploit-explore trade-off, inserting ads, and merchandising.
The motivation behind creating a new search storage engine
As our previous blog posts have illustrated, we have been using cloud-hosted ElasticSearch (ES) as our out-of-the-box storage engine. An open-source project, ES is commonly used as the storage system for search applications.
There are many great things about ES and cloud-hosted operating models. As DoorDash’s business grows and expands, however, there are new use cases that could benefit from a different storage engine. Among the limitations the team encountered with hosted ES are:
- Difficulties with having computation close to storage. Without an extremely fast network – for example, hundreds of microseconds – certain complex retrieval and filtering algorithms would require that the search service make multiple network round trips to storage. A typical intra-datacenter network round trip between two containers through an operating system networking stack could take 10ms; fetching multiple rounds of data could easily become a latency bottleneck. For example, achieving two-stage search in an efficient way becomes challenging without full control of the storage.
- Limited selection of first pass rankers. ES allows only a limited selection of first pass rankers through plugins. The idea is to apply a simple ranking algorithm to scan through storage for the first pass of candidate retrieval. But if we can’t push our code to storage, we can either opt into ElasticSearch’s plugin paradigm or pay the cost of network round trips to do post-processing in the search server’s memory.
- Expensive for high capacity deployments. ElasticSearch becomes expensive as capacity increases. Even after many optimizations to shrink the clusters and with a discounted rate for committed purchase, ElasticSearch generates large cloud compute bills.
Experimenting with other search paradigms
The search team started experimenting with in-house solutions using Apache Lucene, a mature and industry-leading open source technology, which is also what ElasticSearch is based on – we are going right under the hood. In our early results, we observed end-to-end latency reduction of multiple times and an order of magnitude smaller computation cost. The benefits were myriad, including:
- Tight retrieval algorithm control and the ability to push down exact logic close to storage Fast experimentation with first-pass ranker algorithms and textual feature engineering with little operational overhead
- Reduced query latencies through direct leverage of the early termination supported by Lucene, which is also an academic and industry standard method of query processing
In addition to Apache Lucene, the team continues to explore other search paradigms. For example, there are companies already employing deep learning-based embeddings to represent search objects and queries. Some companies are also trailblazing by embedding all things in their systems. In embedding searches, we convert a textual match problem into a high-dimensional spatial search problem. We convert a query to an embedding – for instance a 512-dimension numerical vector – and then conduct a nearest neighbor search among all document embeddings. Searching nearest neighbors for embeddings is a daunting task because of the curse of dimensionality. Fortunately, most of the time we do not need exact KNN — top-K nearest neighbors – and can instead approximate our search problem with ANN – approximate nearest neighbors. There are many researchers and practitioners in the industry who already have been working on this problem for decades. Some recent work includes Meta’s FAISS – Facebook AI Similarity Search – and HNSW, or Hierarchical Navigable Small World graphs and their implementations.
Now that we have discussed how we rebuilt indexing, retrieval, and storage to support search across verticals, we can move on to the second challenge we faced: query and document understanding beyond food searches.
Improving query and document understanding
After discussing scaling our infrastructure for query and document understanding, we needed to move beyond our taxonomy for dishes in restaurant menus to incorporate more verticals. That required extending and defining a new taxonomy to enrich search, leveraging machine learning labeling services through human annotation to bootstrap our new taxonomies, and using natural language processing for the new search experience. Here we demonstrate why it is important to continue investing in this technology.
Expanding on the food taxonomy
As illustrated in our previous blog, having a taxonomy improves our understanding of a consumer’s search intent. Since we adopted our initial taxonomy, we have standardized the methodology and process to design, curate, govern, and operate taxonomies. We now are working on:
- A food taxonomy that includes such things as ingredients, nutrition, dietary attributes, regional cuisines, food preparation styles, and restaurant types

- A retail taxonomy that includes such things as brands, products, nutrition, ingredients, and packaging

- A query intent taxonomy that includes such things as brand, store name, verticals (food, grocery), modifiers (e.g. yellow/small/one-gallon), dietary, nutrition, and ingredients
With all the standardized knowledge about what DoorDash has in its inventory and what a query potentially is searching for, we can optimize our search system to return more relevant results. One challenge, however, is establishing the source of truth.
To a great extent, we have converted an open problem – understanding everything – to a more tractable problem – understanding within an established framework. Even so, we still have far too many dishes and retail inventories inside our databases. Our strategy to contend with the remaining issues is as follows:
- Begin with an unscalable manual approach, which allows us to move fast, verify our assumptions, and iterate, scaling up to hundreds.
- Streamline the manual approach to a standard operating procedure, or SOP, and let our business strategy and operations partners scale the process up to hundreds of thousands.
- Build machine learning models with the data acquired in previous steps to further scale to millions and more.
- Create an SOP for quality checks. Just as every public company is required to have third-party auditing of their financials, we conduct quality checks against our annotated data in steps one through three through sampling. The audited quality evaluation is used to improve the business SOPs as well as fine-tune machine learning models. Quality checks are essential to reduce systemic biases and improve accuracy and coverage of data with taxonomy information.
Using human annotations to create labels
Manual human labeling requires a framework to account for cross rater variance. A standardized process minimizes such variance in our data. Google search has developed excellent guidelines around this process. DoorDash’s search team has partnered with the business strategy and operations teams to come up with relevant annotation guidelines for our company. To delve more deeply into this topic, please review our DSML team’s work on related topics around item embeddings and tagging.
Even if every DoorDash employee were to work full-time following the SOP, we still would not get to all of the hundreds of thousands of annotation tasks. Human annotations must rely on vendors to scale. There are many companies across the world in the annotation business, including Amazon’s Mechanical Turk, Google Cloud’s AI Labeling Service, Scale.AI, Appen, and many more. These vendors take annotation tasks and parcel them out to affiliated human annotators across the world. Because of the human labor involved, vendor prices and capacities vary widely. As a result, properly managing vendors and capacity/budget allocations is a full-time job.
An annotation task usually does not and cannot rely on a single human judgment. A popular way to de-bias is to have a majority vote with a quorum. To ensure a reasonable level of accuracy, we would need three, five, or even more human annotators to conduct the same annotation task. This imposes a higher demand for human labor and budget. Another factor for consideration is the complexity of a task. it is important to have a well-designed annotation guideline so that annotators can conduct their work efficiently and effectively.
After we collect annotations from vendors, we still need to conduct audits. Just as in any system, quality assurance is critical here. When we conducted in-house audits on vendor outputs, we found a few interesting themes:
- Some vendors source their annotators from particular regions, engendering cultural differences that made annotators systemically misjudge a class of concepts.
- Certain vendors trained/maintained better quality annotations than others.
- For some types of labels, our annotation guidelines left too much room for ambiguity.
- Vendors took significantly longer to ramp up and process some of our annotation tasks when we underestimated complexity.
Using natural language processing to enrich query context
In addition to using new taxonomies and labeled data to enrich query understanding, we further explored using Natural Language Processing (NLP) to enrich query context as a scalable approach. The team is just starting to partner with data scientists to apply NLP approaches to query understanding. Here we will focus on a specific application – Part-of-speech (POS) – to highlight NLP’s utility and challenges.
There were two key challenges. First, we needed a performant NLP model to give us good Part-of-speech (POS) annotation. And second, we needed to consider during query processing time how to efficiently obtain such POS annotations.
The model for POS annotation
POS annotation of a query helps us understand its linguistic structure. For example, “red pizza” is parsed as [JJ NN], in which “JJ” is the POS tag for an adjective and “NN” is for a noun. As a result, we know this query contains a structure of “an adjective describing a noun”. During search, when “red pizza” full match is not available, we can relax our query to “pizza” by walking up the hierarchy of taxonomy, which effectively achieves “query expansion” to increase recalls.
Transformer models are very popular today in NLP. There is a plethora of off-the-shelf open source libraries and models. We experimented and found Spacy to be a good library for its ease of use, active community updates, and rich set of models. NLP libraries involve far more than POS tagging; we are excited to continue experimenting and adding more NLP capabilities.
Serving POS tags efficiently
Dealing with our second challenge of serving POS tags efficiently remains an ongoing effort. A transformer model running in Python without optimization kills performance. Because of the Python per-process model, we would pay a very high latency penalty and would need a huge fleet of Python-serving containers just for online inference. We have several options to bring latencies under control: :
- Load offline pre-computed head and torso queries into server storage such as Cassandra, Redis, or CockRoachDB for their POS tags, eliminating the need for online inference for them. Precomputing for tail queries is impractical given the unbounded cardinality though.
- Use a simpler NLP model for online inference. This involves a trade-off between model power and system performance. There are a few JVM-based NLP libraries; DoorDash runs microservices in Kotlin, so JVM libraries are good for us. There are two notable popular choices: Apache OpenNLP and Stanford CoreNLP. The first one is open source under Apache license, making it free to include. CoreNLP is under full GPL license, but the library owner offers license purchase for commercial use.
- Go deep into Python and neural network internals to solve the performance issue inside Python runtime. This is doable with in-depth engineering investment; Roblox recently showed that they were able to serve one billion online BERT inferences daily.
Because we are just starting to apply NLP techniques to search, we are only scratching the surface of this decades-old, well-researched field. We will publish more about our endeavor in this area as the team makes more progress.
Learning-to-rank
Our remaining challenge is how to bring better relevance to search results. After we retrieve data from search storage systems, we need to rank them according to relevance. There has been an evolution of learning-to-rank technology at DoorDash. After that we will show it is critical to define a search evaluation framework and which learning-to-rank techniques have helped us improve relevance.

We began with a simple heuristic-based ranker based upon content popularity and lexical similarity – BM25 – (as described in our last blog post) as an out-of-box solution from ElasticSearch. Besides BM25, PageRank and probabilistic language modeling have demonstrated their success in the information retrieval domain and prevailed with “unsupervised” approaches.
Combining different ranking heuristics is not trivial, however, and eventually becomes unscalable when the business/product continues to grow and search behavior becomes more diverse. Performance also can be suboptimal and inconsistent. The heuristic ranker works most effectively when a consumer searches for a specific merchant name, which is called branded search; otherwise, the relevance pales.
At the end of 2020, we started to introduce the learning-to-rank, or LTR, technique to improve search performance based on a machine learning framework.
From a pure rules-based string match ranker to a more sophisticated ranker, we think there are some common learnings we could be sharing. Search evaluation is critical to establish a principled framework that assesses search result relevance.
Human evaluation for relevance metrics and training data
Before the data/ML-driven approach kicks in, it’s important to set the first principle for search relevance: the ultimate consumer experience that we are trying to deliver and the optimization goal. Until we do this, data plays a vital role in providing valuable information first for evaluation and then modeling.
Prior to the first LTR model, we put in significant effort to establish the online search evaluation framework and methodology up front.
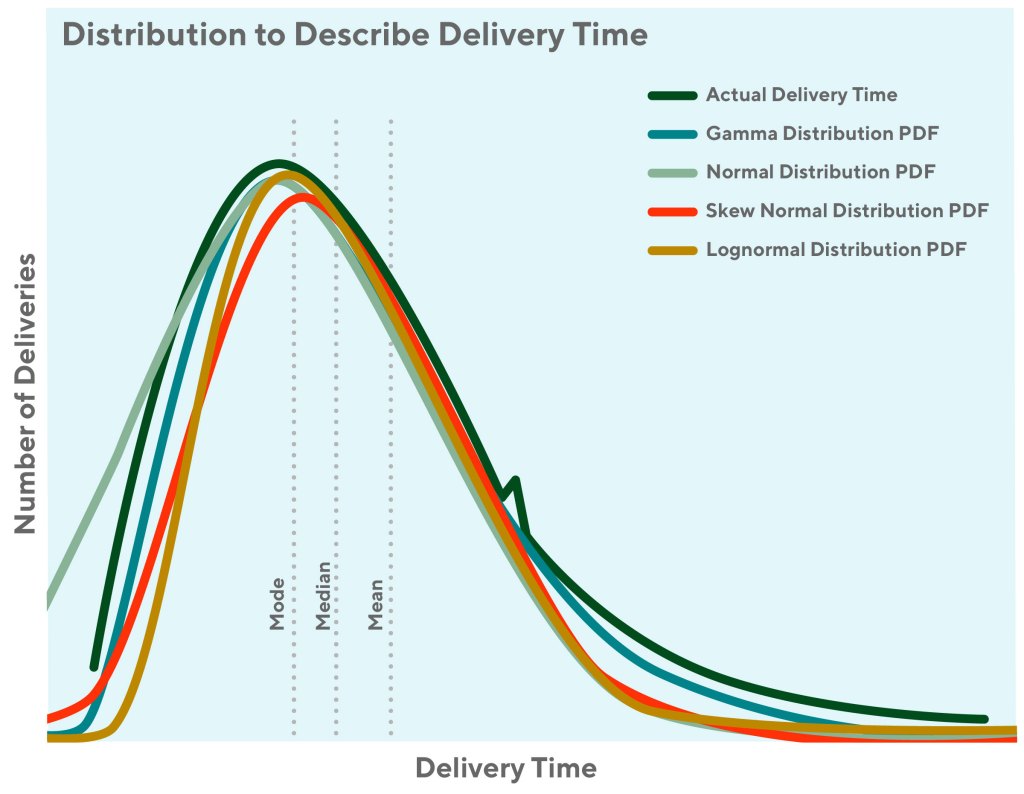
We established two categories of metrics: business vs. information retrieval. For business metrics, search conversion rate is the north star along with a set of input metrics – examples include click-through rate, search usage, and first-click/converted rank position.
For information retrieval metrics, the first step is to define search relevance. From the beginning, we leaned primarily on consumer engagement as implicit feedback and assigned varying weights to different engagement types – for example, click and conversion – as a perceived relevance score. Accordingly, we built mean-reciprocal rank and normalized discounted cumulative gain (NDCG) to evaluate search quality beyond materialized business impact.
The implicit feedback serves as an effective data signal for both evaluation and modeling in the short- to mid-term, especially for head-and-torso queries in which the consumer engagement information is rich and relatively cheap to acquire. To comprehensively measure any nuanced search quality improvement and drive the performance for tail queries, however, we later introduced the human-in-the-loop method and lean heavily on operational excellence to collect more reliable signals and slice-and-dice search quality from 360 degrees. The team is currently revamping the next-gen evaluation system; we show only current high-level conceptual flow in Figure 5 below. We will publish a future blog post to dive deeper into our next generation quality evaluation system.

Pointwise ranking
After defining the search evaluation framework, our next step was to build learning-to-rank models and apply them to production. We started with pointwise ranking, a well-studied learning-to-rank paradigm. Given that search conversion rate is our north star metric, we directly train an ML model to predict the view-to-conversion rate for all the stores retrieved by a specific search query.
We leverage search logs and store metadata to engineer four types of input signals, including:
- Query features, which characterize the query type – branded vs. non-branded – query length, click-through rate (CTR) and conversion rate (CVR) of the query
- Lexical similarity features, such as Jaccard similarity and string edit distance between query and store metadata
- Store features, or historical CTR and CVR in such things as search, total sales, rating, price range, or ETA
- <Query, Store> pairwise features, including historical store impressions, CTR, and CVR for a specific query.
The first LTR model was trained using gradient boosted decision trees and was evaluated on a separate dataset. We leveraged the Bayesian approach for hyperparameter tuning and area-under-the-curve (AUC) gain for offline model selection.
From heuristic ranker to having an ML-empowered LTR, we have observed an immediate big leap in all consumer engagement metrics with search.
Behind the scenes, however, it took more than six months from model development to final deployment. Significant effort went into building a system surrounding ML so that we could seamlessly build and deploy, iterate, and measure the ML performance. The context of an end-to-end ML pipeline is far beyond building a performant offline model. ML technology at DoorDash also has improved significantly since then.
The second big leap happened when we introduced personalization features into the LTR model. At DoorDash, our search has two distinct usages:
- Brand search, in which the consumer searches for restaurant names with navigational and highly focused intent, and
- Non-brand search, in which the consumer searches for a certain cuisine type or food category, usually through cuisine filters. The intent to convert is largely driven by personalized preference.
When introducing consumer specific signals into the LTR model, we have seen a substantial boost in core business metrics. Indeed, the improvements are mostly from non-branded searches, which take a sizable chunk of the search volume.
Conclusion
To expand from a focused food delivery search engine to a general platform that allows searching for everything, we needed a holistic approach that touches almost every aspect of a search system including search infrastructure, query and document understanding, and learning-to-rank. We showed how to build a more reliable indexing architecture to shorten indexing time with realtime updates. We also showed how to federate searches across verticals for efficiency and effectiveness. We believe it’s worth pursuing new types of search storage engines instead of betting on third-party solutions. For query and document understanding, we showed practical considerations and lessons defining and collecting data for a new taxonomy. We believe continuous investment in natural language processing will yield big gains for us. Finally, we discussed the evolution of learning-to-rank technologies at DoorDash and how we established our evaluation framework and leveraged specific ranking techniques.
We plan to publish future blog posts by our DSML teams about search dedicated to machine learning details focusing on pairwise ranking and deep learning. We are constantly making improvements to our search performance and relevance. We hope to meet you again in the near future in another blog post!
Acknowledgements
Many people from search and new vertical engineering teams have contributed ideas to make this blog post come to life: Aleksandr Sayko, Kostya Shulgin, Qihua Yang, Jimmy Zhou. We are also grateful to the DSML teams for their contributions in ML modeling. Finally, we would like to thank the leaders in engineering, S&O, analytics, product and DSML: Prasad Sriram, Tian Wang, Tarun Bansal, Melissa Hahn, Oliver Davies, Jessica Zhang, Akshad Viswanathan, Parag Dhanuka, Han Shu, and Kurt Smith.