As part of our ongoing efforts to enhance product development while safeguarding app health and the consumer experience, we are introducing metric-aware rollouts for experiments. Metric-aware rollouts refer to established decision rules to flag issues with automated checks on standardized app quality metrics during the new feature rollout process.
Every action DoorDash takes focuses on enhancing the consumer experience. Through deploying metric-aware rollouts, we aim to prevent performance degradation and other problems for our customers when we add new elements or products. This new feature allows us to experiment and innovate while continuing to safeguard app health and deliver a delightful user experience.
Navigating product development risks
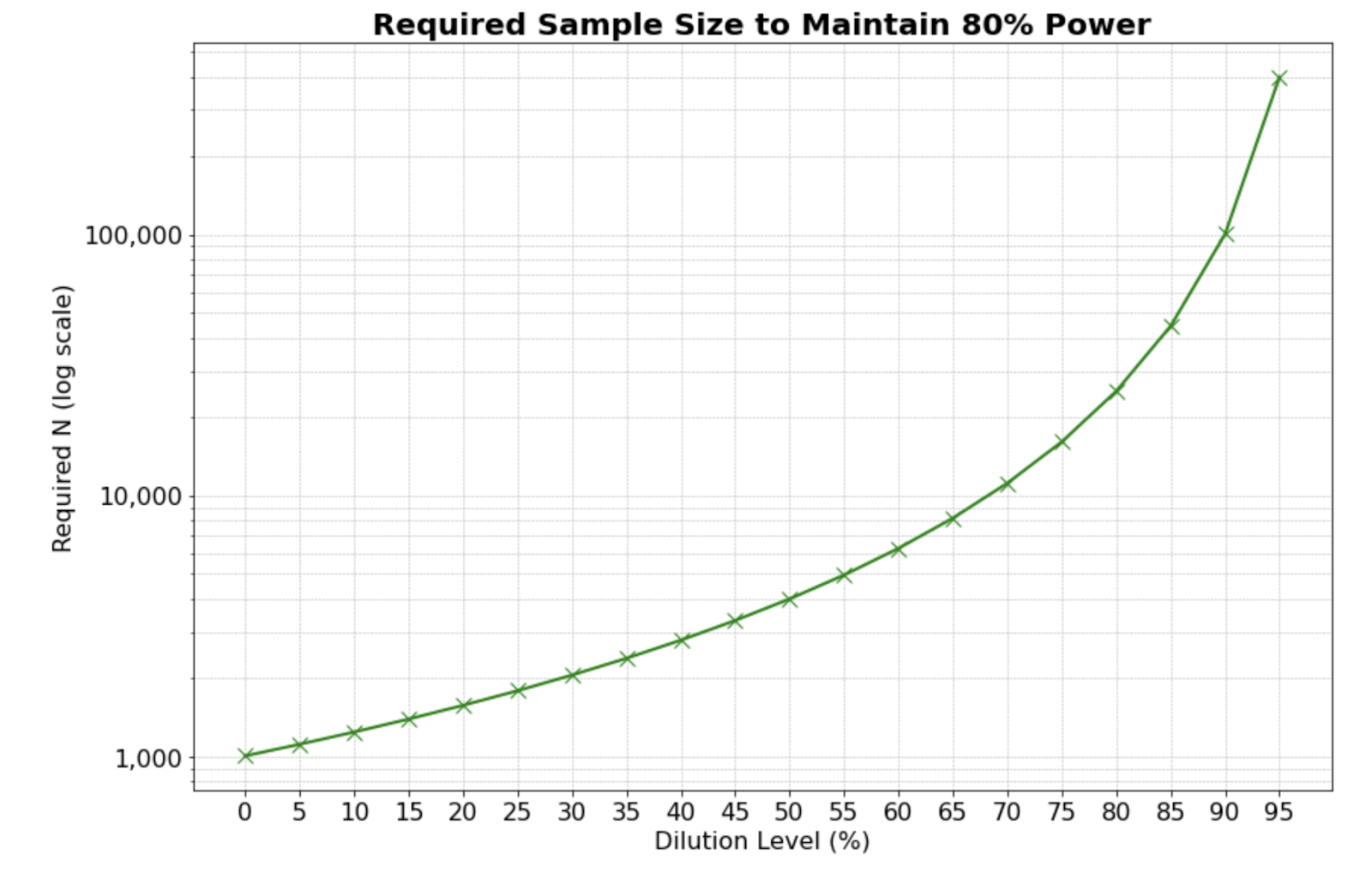
Product development inherently involves risks. Experimentation and rapid product releases can lead to unexpected consequences. At DoorDash, we have occasionally seen such unintended effects in the form of increased app latency, higher error rates, and — in extreme cases — app crashes. Shipping experiments could potentially degrade app latency, directly impacting the consumer experience, which is always at the forefront of our minds
The key issues before implementation of metric-aware rollouts include awareness, metrics and process standardization, and traceability. Lacking app quality metrics leaves experiment owners in the dark about app degradation. Without standardized metrics, app health tracking becomes inconsistent. Problematic rollouts are not paused or blocked when metrics degrade. Metric owners and app page owners don’t know which experiments are impacting metrics, meaning it can take several weeks to identify the cause of degradation. The absence of a systematic detection mechanism for app quality degradation creates significant challenges for both metric/product owners and experiment owners:
- App quality metric/product owners face a labor-intensive process to identify which experiments are causing app quality degradation; this often involves manual tracking and analysis. Without a detection system, problematic experiments may reach full rollout, exacerbating issues.
- Experiment owners may not know which app quality metrics to monitor and what actions to take when these metrics show statistical significance. Interpreting results can be challenging, leading to frequent consultations with metric owners.
To address these challenges, the automated guardrails introduced by metric-aware rollout allow iterating and releasing products in a more controlled manner, balancing speed and quality through implementing scalable, automated solutions to mitigate app quality risks. Through more measured across-the-board tracking, we can ensure our experiments are both innovative and safe, ultimately enhancing the product development process and protecting the consumer experience.
Enter metric-aware rollouts
Metric-aware rollouts address these issues with automated checks on standardized app quality metrics. With this new process, we automatically pause rollout and alert the experiment owner when degradation is detected. This ensures consistent measurement and immediate response when deviations occur. Here’s how we achieved this:
(1) Standardized metrics: App quality metrics are now uniform across all experiments with two layers of metrics for quality checking.
- Composite metrics or a single metric measure the percentage of page load and page action events that are deemed as “bad” — for example, encountered poor latency or an unexpected error or crash on any platform, including iOS, Android, or the web. By minimizing the number of app quality-related sub-metrics that the experimentation platform needs to check, we reduce the risk of false positives and computational cost/time.
However, in the case of statistical significant degradation in any of the three composite metrics, we added a second layer of supplementary checking to democratize the debugging and diagnostic process and encompass a more granular view of our app quality status.
- We break down app quality measurement into five sub-metrics, each with a corresponding page- or action-level dimension cuts to let experiment owners easily pinpoint the exact issues within each experiment.
- Page load duration P95
- App: Measures the time from the empty screen display to the data being fetched, processed on the clients, and updated on the screen.
- Web: Measures the time from a page request until its largest element is visible on the screen, i.e. LCP time.
- Dimension cuts: All core T0 pages
- Action load duration P95
- App: Measures the time from the user interface receiving user input events to the action being successfully completed.
- Web: Measures the time from initiating a GraphQL call to the client receiving a response within an action.
- Dimension cuts: All core T0 actions
- Unexpected page load error
- App & web: Measure the percentage of unexpected errors encountered out of all page load events, where unexpected error is defined as errors caused by the app, hence fixable on our end.
- Dimension cuts: All core T0 pages
- Unexpected action load error
- App & web: Measures the percentage of unexpected errors encountered out of all action load events.
- Dimension cuts: All core T0 actions
- Crash
- App & web: Measures the percentage of crashes encountered out of all page load events without errors.
- Dimension cuts: All core T0 pages
- Page load duration P95
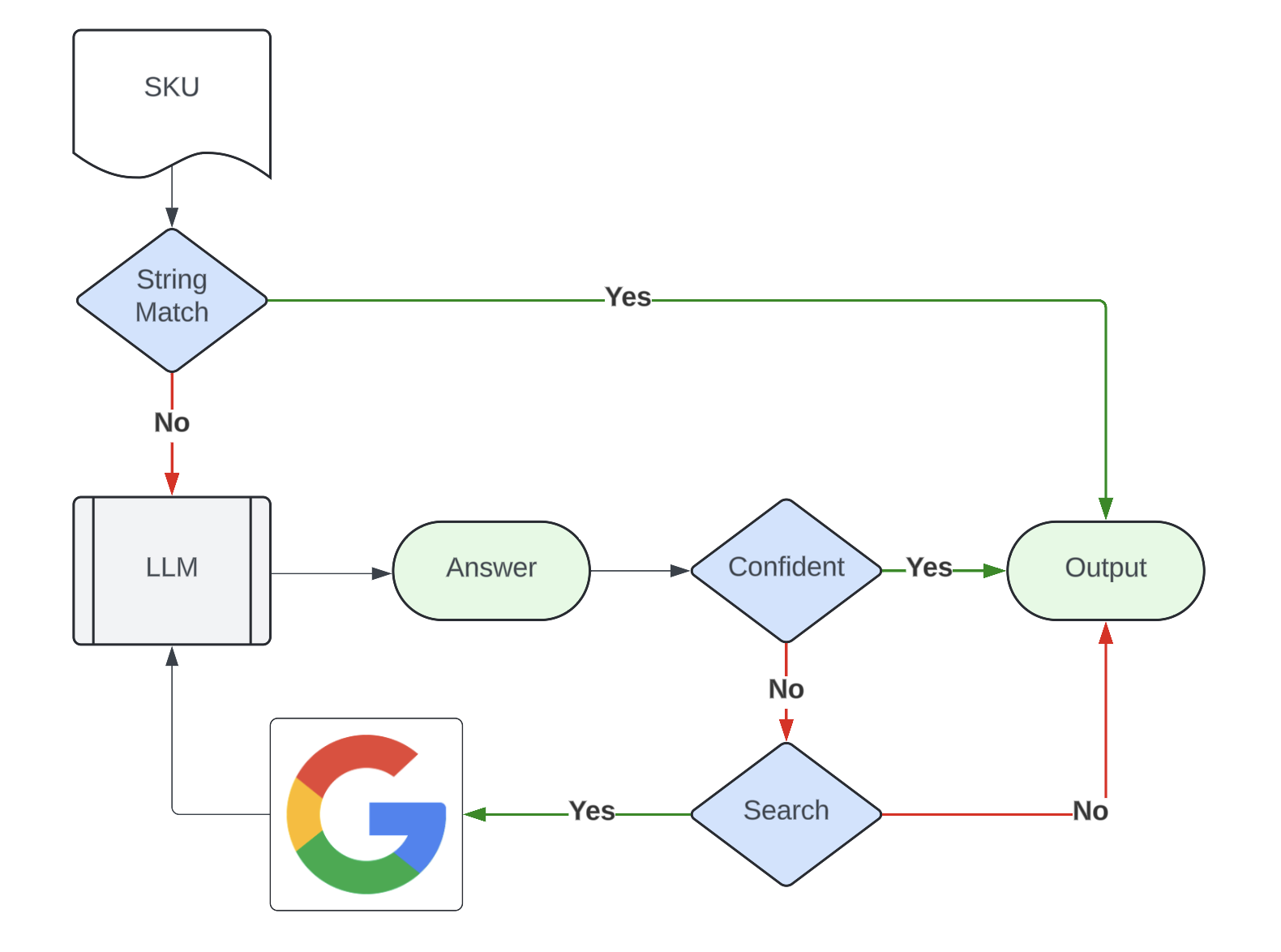
(2) Automated analysis, tolerance configuration, and false positive control: App quality analyses are automatically created with analyzed metrics to thoroughly examine whether the experiment has led to any significant degradation in app quality.
The analysis follows the decision-making process outlined below. This automation streamlines complexity for users by considering the following factors:
- Experiment robustness: All experiment health checks are taken into account to ensure the setup is robust and the results are valid.
- False-positive control: Addressing false positives typically requires specific knowledge; however, our process handles this complexity through Multiple Hypothesis Testing correction and sequential testing.
- Tolerance for degradation: We introduce the concept of tolerance because we recognize that some degree of regression on app quality metrics may be acceptable during feature development. This allows metric owners to configure tolerance levels for each app quality metric independently. We assess against these thresholds to detect significant degradation.
With the experimentation platform handling decision-making complexity, both experiment and metric owners can proceed confidently with their respective tasks.

(3) Automatically disabled rollout or rollback: If degradation exceeds the set threshold, the rollout is paused or blocked to protect app health. Experiment owners receive alerts and can take immediate action.
Approval process and budget framework
For DoorDash to be competitive, we know we must quickly iterate ideas that are worth pursuing. During the experimentation phase, we do not expect the teams to hyper-optimize performance; instead, we encourage them to prioritize fast learning and only invest in optimization after the business value is proven. As a result, some experiments will negatively impact app quality.
We create a budget framework to allow experiment owners to roll out features that have short-term negative app quality impacts; owners remain responsible, however, for repaying those negative impacts through a clawback plan.
When a quality regression below the metric’s tolerance threshold is detected by the metric-aware rollout system, the experiment team must prepare a clawback plan and obtain sign-off from the metric owner team before continuing the rollout. The clawback should be prioritized for action no later than the following quarter. But if the regression exceeds the tolerance threshold, further rollout is blocked unless the experiment team obtains an override approval from leadership.
Impact on DoorDash and beyond
Implementing metric-aware rollouts provides significant benefits, ultimately enhancing the experience for our customers and our engineering team.
- Enhanced visibility and diagnosis: By standardizing app quality metrics, we ensure that all consumer tests are visible, allowing for effective diagnosis of any issues. This means we can quickly identify and address problems, maintaining the high quality our customers expect.
- Rapid response: With the ability to automatically pause or block experiment rollouts when issues are detected, the time from experiment start to rollback is significantly reduced. This proactive approach safeguards app health and ensures a consistently delightful experience for our customers.
- Proactive management: Experiment owners can now monitor the impact of their projects on app quality in real time. They can identify the root causes of any degradation and take immediate action to rectify the issues, ensuring our app remains reliable and user-friendly.
Our commitment to metric-aware rollouts is not just about operational efficiency; it’s about delivering a seamless and enjoyable experience for our customers. By proactively managing and maintaining app quality, we ensure that every interaction with our app is positive and frustration-free, reinforcing our dedication to customer satisfaction.
Broader implications
Metric-aware rollouts mark a significant step forward in safeguarding app health and consumer experience. By addressing key challenges in our development process, we have created a scalable and automated solution that mitigates risks while maintaining our product development momentum.
While initially focused on app quality, our approach to metric-aware rollouts has the potential for broader applications. It provides a robust framework for managing risks across various metrics, potentially extending to other business guardrails. This standardization can streamline decision-making processes company-wide, ensuring consistent and reliable product development.
Looking ahead, we plan to expand this feature to additional company guardrail metrics, implementing smarter systems for metric association, monitoring, and reducing false alarms. Ultimately, we aim to enable auto-rollout and rollback of experiments, further enhancing our ability to innovate safely and efficiently.
This is just the beginning of what metric-aware rollouts can offer. As we continue to refine and expand this feature, we anticipate even greater improvements in app health and consumer experience, setting new standards for excellence in product development.
Acknowledgment
Without a doubt, building such a safeguard framework to support a diverse set of use cases requires collaboration between various teams, including design and build of the feature on the experimentation platform — Erich Douglass, Eric Liu, Jonathan Orozco, Baldomero Vargas, Yixin Tang, and Drew Trager; insights from the consumer platform team — Daniel Hartman and Akanksha Gupta; and Pradeep Devarabetta Mallikarjun from the Dasher team for enabling this feature on Dasher experiments.