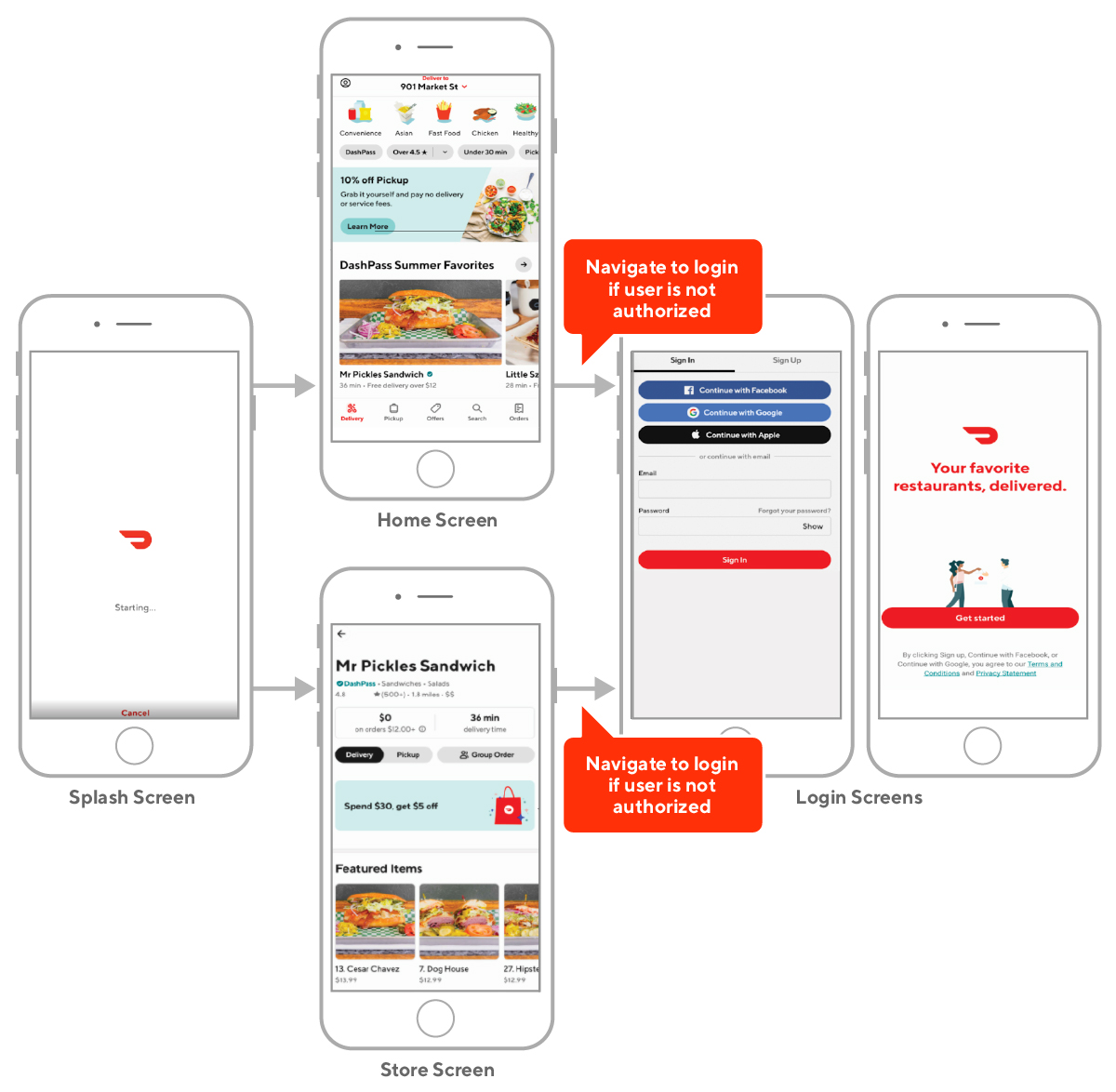
When DoorDash added a pickup option for customers, complementing our existing delivery service, we needed to build a map to ensure a smooth user experience. A map tailored to pickup users could show nearby restaurant options, enabling customers to factor in distance to their selection process.
We successfully implemented such a map in our mobile app and saw positive results from our customers, indicated by increased conversion rates. We wanted to replicate that success for the DoorDash web experience, giving our customers yet another option when ordering.
However, when implementing a pickup map for our web experience, we encountered a number of challenges. To maintain performance and a rich featureset, we needed to carefully design its underlying architecture and APIs. Unlike mobile apps, geolocation is not a given for web applications, so we had to make some important choices around determining the customer’s location.
Designing a pickup map for DoorDash
When DoorDash added a pickup option to our web experience, we wanted to build a map to improve the user experience (UX), which had been a successful feature on our mobile app. A pickup map displays all the restaurants near the customer’s current location and includes a carousel for recommendations. DoorDash did not previously have a map because when our business was only deliveries, customers only needed the restaurant’s name and the estimated delivery time, which was best displayed as a list.
When we introduced the pickup option, adding a map to our mobile app improved the UX because pickup users require information about restaurants’ locations relative to theirs. And beyond the functional aspect of showing a customer how to get to a restaurant, the map also lets customers browse for options nearby.

What we learned when implementing a pickup map at DoorDash
Building a pickup map for the web experience has some technical complexities. Firstly, it required thorough design and planning to make it integrate with our web framework. Secondly, we had to make some technical choices on which location and map APIs to use.
Lesson 1: Build a custom map library
Having our own map library allows us to future-proof the application, since it gives us the full control and flexibility we need to easily add new features and integrations. When integrating the Google Maps platform we considered many libraries to connect with React, our chosen frontend framework. These libraries could be used to save time and simplify the overall implementation. In the end, we decided to build our own map library, in order to optimize flexibility and performance. Building our own library gave us full control of the integration between the Google Map API and our React components, avoiding any potential limitations introduced by a third party library.
Having our own library also ensures that future integrations and changes are smooth and easy to build. For example, we had planned to add a recommendation list in a carousel format after launching the initial pickup map. Since we had built our own library, we were able to move fast without having to make any trade-offs or hacky decisions.
A custom library also helps optimize performance by ensuring there are no extra unused features. While we plan on adding a lot of additional features, we also wanted to make sure that our application runs as smoothly and quickly as possible. Therefore we decided to build our own library since using a third party library means including many extra features, which we were not ready to use.
For example, the only features we needed from the Google Maps API were click and hover interactions, which are not worth the performance cost of implementing the entire library. By building our own library we ensured that we only used the features that we needed, enabling us to optimize for performance.
Lesson 2: Understand the pros and cons of using the Geolocation API
When designing the pickup map, we wanted to make sure that our customers would be able to search for restaurants based on their current location or delivery address. On the web, one of the best options to get a user’s current location is the Geolocation API from the browser. We chose the Geolocation API over other alternatives because it’s native to the browser, which means it won’t hurt the web app’s performance. Nevertheless, there are several pros and cons when it comes to the Geolocation API that will shape how to use it effectively.
Pros:
Two of the main advantages of using the Geolocation API are its native browser support and simple API interface. The Geolocation API is native to most browsers including Internet Explorer, which means no additional libraries need to be imported and there is no incremental overhead on the web app’s bundle size. This lack of overhead helps us optimize performance.
Besides that, the Geolocation API has a pretty simple interface that makes it easy to integrate into the web app. We merely need to type navigator.geolocation.getCurrentPosition to start the API integration process. Writing a lightweight wrapper for whichever framework is being used is extremely simple as well. We wrote a hook to tie the Geolocation API usage to our React component life cycle in less than a day. Overall, the native browser support and the simple API interface are the main advantages of using the Geolocation API and main reasons why we chose it.
Cons:
However, the Geolocation API does have a few drawbacks. In some scenarios, it can be slow to retrieve locations. In addition, the API’s interface for prompting the user to grant permission to get their current location is not ideal.
First, getting the user’s location through the Geolocation API can be slow depending on the region and connection speed. This slowness results in a blank screen until it’s received, which might result in a customer giving up on placing an order.
However, it’s possible to disable the high accuracy mode from the Geolocation API, potentially resolving the blank screen problem. This high accuracy mode requires more resources on mobile devices, so by disabling it we will be able to get the user’s location more quickly.
Second, the Geolocation API does not come with a great interface for prompting the user to give the web app permission to access their current location. When implementing features like the pickup map, it is usually required to know if the user has already given permission to get their location, so that the web app would use the correct location to initialize the search.
Out of the box, the Geolocation API actually doesn’t have a method to simply retrieve the user’s permission state. In fact, the two main methods for getting locations initiates two actions: prompting users for their permission and fetching their current locations. These two actions cause some difficulties when separating permission management from getting locations.
One way to improve this poor user interface for getting permission to retrieve the user’s current location is to utilize the Permissions API. A native browser API, the Permissions API works better than storing the user’s permission data in local storage or cookies, which is a common way to solve the issue of the user’s permission state.
However, the data stored in the browser can become outdated quickly. If the user manually changes their permissions, the data stored won’t be updated automatically. Instead, the Permissions API is designed to solve the permission problem by providing straightforward methods to query the user’s current permission status on any browser’s APIs including the Geolocation API. The use of the Permissions API will always return the correct status. Unfortunately, the Permissions API is not supported by Internet Explorer or Safari, which limits this method for a significant portion of users.
Lesson 3: Always include a fallback mechanism
It’s essential to offer a fallback mechanism in case the Geolocation API returns an error, so that the user experience is not negatively impacted. Errors usually come from a denied permission request or from a timeout. In fact, it is recommended to always assume that users will block a permission request.
For example, a fallback option could be the user’s default address in the system if the current location is not available. If the default address is not available either, another option is to derive a location from the user’s IP address. These fallback options ensure that we always have an address on hand to show restaurants nearby. In summary, assume users will not share their current location and plan the fallback experience accordingly.
Lesson 4: Make sure to plan out all interactions in detail
Because a map’s interactions and features can be quite complex, it’s important to plan all these out with a product manager and product designer to ensure success. Maps have a lot of edge cases. For example, what happens when two restaurant pins are very close, making it difficult to accurately select one? Figuring out all these edge cases in advance will prevent future bugs and ensure a more complete product.
It’s also important to understand the technical limitations of each technology being used, since technical limitations restrict what can be built. Here are some examples we ran into:
- We could only conduct searches based on a set radius around a center point rather than within map boundaries. The map boundaries were rectangular but search results would only appear in a circle around the map’s center point, meaning that we either had to enlarge the map boundaries or exclude results in the corners of the map.
- The Google Maps API does not support panning from point A to B if the distance between them is too large, instead jumping between the two points. This jump creates a jarring user experience, since the user would see a sudden change on the map without any context of where the change came from.
- Out of the box, the Google Maps API does not have great support for styling label text. It only allows changes to basic styles such as the font family and font size, but not background color, which is very important for ensuring the visibility of overlapping label texts.
No matter what libraries are chosen, or even the in-house APIs, there are going to be some restrictions that will need to be dealt with. Technical limitations usually have an impact on not only the design, but also the product side as well. Therefore, it’s important to let all stakeholders know and make sure everybody agrees on the alternatives.
Conclusion
Many companies need to improve user experience by building a user map to nearby services, and there are tons of ways to implement them. Every choice matters and has a profound impact on the product in the long term, so we think it is extremely important to choose what makes the most sense. Our lessons from the DoorDash pickup map project will help anyone build a similar map and decide which technologies to use, and make the best decisions based on their goals and needs.
Future work
In the future, we are going to create different types of filters and searches for our pickup map. These would improve the UX by helping customers narrow down and find the restaurants they have in mind. We also intend to adopt the Permissions API to ensure the user’s permissions are as up to date as possible. The Permissions API would help bridge the gap between customers and our app on permission statuses.
Furthermore, we aim to improve the web app’s performance by examining how the page components interact with each other, the backend services, and the map library. These optimizations would ensure that the customers can use our app seamlessly with any connection speed.
Header photo by Thor Alvis on Unsplash