Many tech companies, including DoorDash, Amazon, and Netflix, greet users with an explore page to help inspire their shopping experience. These explore pages often present a large amount of content, making it a challenge for the backend system to serve them at scale.
DoorDash’s explore page shows a mix of restaurants and food items we recommend to each user based on their past activity. In our efforts to improve the user experience, we Increased the complexity of serving up these pages by including carousels and category listings to offer a relevant, visually engaging selection of nearby food options.
Our growth over the last few years made it clear that the system we used to serve up explore pages did not scale, as it made repeated, duplicative calls to downstream services. Implementing a more agile, scalable system involved creating a new pipeline design pattern to serve our explore page content.
Problems with serving our explore page
At DoorDash, our explore page provides a list of recommended restaurants and stores based on the user’s engagement history and location. We display elements such as carousels, banners, and collection tiles for users to scroll and explore the options they might like.
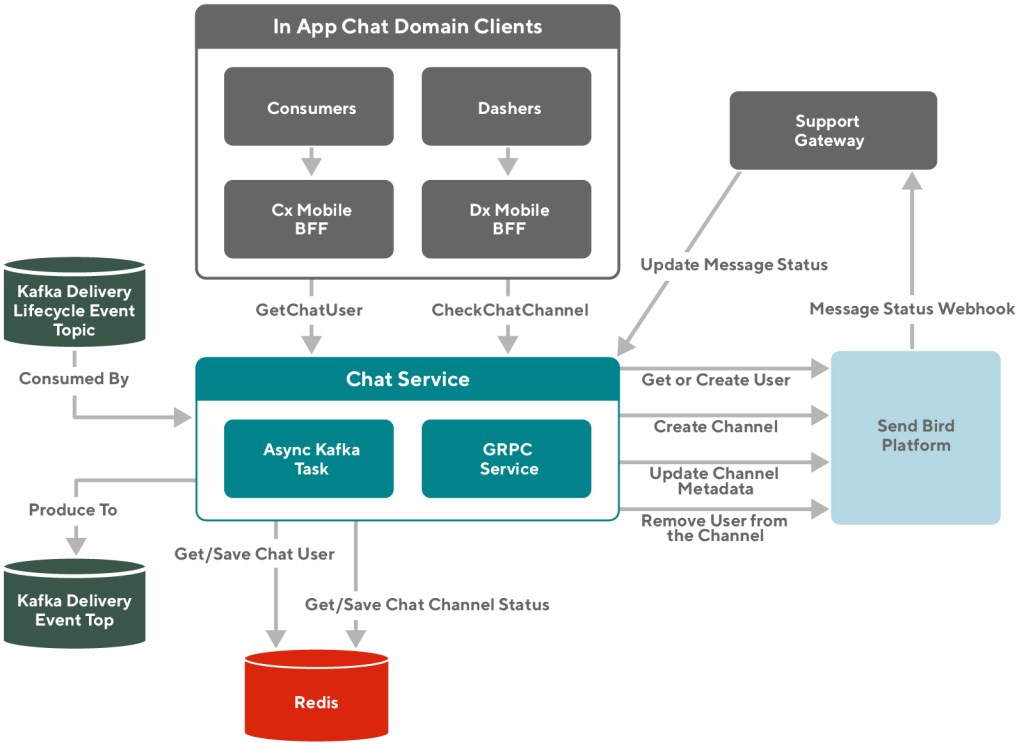
We use a microservice called the Feed Service to power our explore page, which serves as the entry point for requests during the entire consumer session. The Feed Service orchestrates request responses by fetching data from different content providers, adding context, and building personalized display modules as a feed-style response before returning back to the clients.
However, the Feed Service’s previous system faced several limitations, making it difficult to scale the explore page with more restaurants, stores, and carousels.
Inefficient calls to other systems
Our explore page made an unnecessary amount of calls to downstream services to get the information it needed to show results to users. For every carousel we built, the system repeated the same discovery flow of retrieval, ranking, and content hydration, making duplicative content calls. As the number of carousels we served increased, this inefficient system could not scale.
Inter-carousel ranking limitations
The ranking process, which determines the order we show selected restaurants and stores on the explore page, was performed within the same service, called the Search Service, as the retrieval process, which meant that ranking could only be done among the stores or restaurants being retrieved. Because we fanned out the retrieval flow for every carousel, the ranking could only be done within the carousel. This approach prevented us from organizing the carousels in the most optimized manner for users, and further stopped us from showing more carousels when we could not use ranking to select the most relevant ones.
Minimal modularization
As mentioned above, each discovery flow can be broken down to retrieval, ranking, and content hydration steps. But these steps are not extracted or distilled out of an existing service. For example, candidate generation functionality is implemented separately across multiple applications which have strong overlapping functionalities. The lack of modularization in this system made the continuous development overhead proportional to the complexity of the existing logic, as any updates to candidate generation needed to be duplicated in all instances.
Modularizing with a pipeline design pattern
We converted the existing serving paths in the Feed Service from highly imperative to somewhat declarative with abstractions. We structured the system into a pipeline (a.k.a workflow) design pattern by grouping common functionalities into the same module and including an operator, such as a job or node, in the pipeline. For example, we abstract the concepts of candidate retrieval and store fetching from the Search Service as one specification of a candidate generation operator. Similarly, we can have more operators for ranking, content hydration, and post processing. Individual operators have standardized framework-level support for guardrails, observability, and context propagation.
Running jobs with a DAG-based pipeline
We use a DoorDash-developed execution core called Workflow that dispatches threads and coroutines based on directed acyclic graph (DAG) dependencies and executes the actual jobs. As mentioned above, each job in the pipeline represents a module of common functionalities, which serves as a higher abstraction, and can be:
- Evolved by more complex implementation.
- Extended by other explore applications which share similar workflows.
As shown in Figure 1, below, the new explore page content generation process can be broken down into the following jobs:
- Candidate Retrieval: Fetch data sources from external services that provide the content of the page, such as the Search Service for stores and the Promotion Service for carousels’ metadata. In this case, we only fetch data sources once for the contents on the entire explore page to avoid duplicate calls.
- Content Grouping: Grouping content into a set of collections that can be later used for ranking and presentation, such as grouping stores based on association of carousels or store list on the explore page.
- Ranking: Rank the entities within each grouped collection. This step involves resolving the correct model ID, generating the feature values, and making a call to the machine learning prediction service to compute the scores for each ranked candidate.
- Experience Decorator: For the unique set of stores across all collections, we need to hydrate them from external data sources for more user experience-related information, including fetch ETA, delivery fee, images URL, and ratings for stores being displayed.
- Layout Processor: This processor collects all the data being fetched and produces placeholders for different presentation styles, including the explore page, form data models for carousels, store lists, and banners.
- Post Processor: Rank and post-process all the elements, such as carousels and store lists, on the explore page that are being processed so far in a programmatic way to optimize the user experience.

Separating ranking from retrieval
Transitioning ranking from the Search Service to the Feed Service makes the Search function a pure recall dependency while leaving the Feed function responsible for personalization precision. This change means we are now able to perform personalized ranking both within collection elements, such as carousels and store lists, as well as across them. Each user will see a completely personalized explore page with ranked elements, along with individual elements showing ranked restaurants and stores.
Having the ranking module inside of the Feed Service lets us implement more complex features into a separate service which governs all business logic relating to recommendations and personalization. Used in this way, the ranking module becomes a lightweight abstraction making the Feed Service more scalable.
Improving Observability
We can introduce system telemetry on top of our pipeline, in addition to the existing consumer telemetry data from end-user applications, as shown in Figure 2, below. The telemetry automatically captures workflow components’ context and results, enabling standardized collection of high fidelity details, essentially letting us know what happened and why within the system. Engineers and functional stakeholders will be able to tap into this data through a self-service interface, providing an in-depth understanding of the quality of our personalization algorithms.

Results
This project was successful in many ways, as it builds a flexible architecture for DoorDash to scale in the years to come, unlocks opportunities for more personalized products and features, and sets the foundations for new discovery-like applications.
Reduce computing resources
We saw tremendous improvement in system metrics in all downstream services. In particular, we observed:
- 35% p95 latency reduction for the explore page feed endpoint and 60% CPU reduction from the Feed Service.
- 80% queries-per-second reduction and 50% CPU reduction from the Search Service.
- An overall reduction of an estimated 4,500 CPU cores usage.
Unlock cross-carousel ranking
The new system has enabled us to experiment with algorithms that rank across all elements on the explore page, including carousels, store lists, collection tiles, and banners, to ensure that:
- The most relevant content ranks at the top.
- Less relevant content can be trimmed from lists and other display elements, reducing the page size.
Build foundations for other applications
We extended the workflow design pattern to other explore-related applications using a similar sequence of operations, such as search and cuisine filters, convenience store pages, and offer hub pages. As each module is an abstraction, each application can either have its own implementation of the module or share the generalized implementation. This change improved both our development productivity and made code maintenance much easier.
Conclusion
To sum up, like many tech companies, DoorDash faces the challenges of scaling its explore page for recommending the best content to users. However, our previous Feed Service-based system had several limitations. We solved our scaling challenges by introducing a pipeline design pattern which modularized each common operator, resulting in a great improvement in efficiency both in terms of system and development.
Although the new system has been a success, by no means will it be the last iteration of our continuous improvement on optimizing DoorDash’s explore experience. There will be more iterations on fine tuning each module of the system to become more efficient and flexible, such that Feed Service can become more lightweight and scalable for DoorDash’s rapid growth in the years to come.
Engineering teams tackling scaling problems might find a solution in the pipeline design pattern. It allows for modularization of components in a workflow, creating a more flexible system with functions that can be used in multiple applications and features. It can also lead to significant efficiency gains through elimination of duplicative code and processes.
Acknowledgements
Thank you to Jimmy Zhou, Rui Hu, Sonic Wang, Ashwin Kachhara, Xisheng Yao, and Eric Gu for their involvement and contribution to this project, and special thanks to Yimin Wei for building the Workflow execution engine.

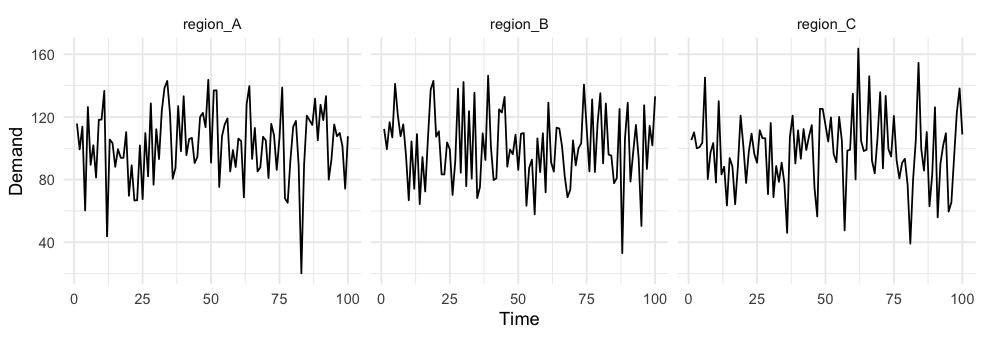
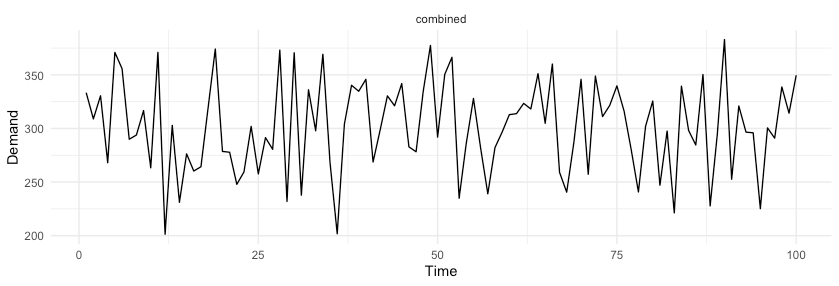
 , which gives us a coefficient of variation of the combined forecast of 14.4%. By simply aggregating random variables, we were able to reduce variance with respect to the mean by over 40%.
, which gives us a coefficient of variation of the combined forecast of 14.4%. By simply aggregating random variables, we were able to reduce variance with respect to the mean by over 40%.