As DoorDash continues its rapid growth, product development must keep up the pace and move new features into production faster and with high reliability. Shipping features without previewing them in the production Kubernetes environment is a risky proposition and could slow down the product development process because any bugs or defects would send everything back to the drawing board. In a Kubernetes environment, developers must build, push, and deploy docker images in the cluster to preview their features before they are pushed to production. This previewing process was too slow for DoorDash’s needs, so the development productivity team had to find a way to build a faster feedback loop.
As an initial workaround, teams built ad-hoc scripts that leveraged Kubernetes port-forward to access service dependencies running inside the cluster from developer workstations. These ad-hoc scripts created a fast feedback loop for developers to run their microservice locally with actual service dependencies.
A fast feedback loop — as shown in Figure 1 — improves the process of verifying code changes with real service dependencies, increasing developer velocity and reducing the feature launch time because issues are found much earlier in the development lifecycle.
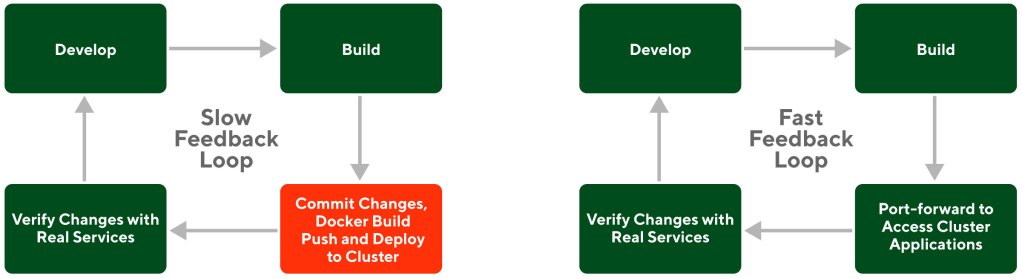
While we initially relied on Kubernetes port-forward to create a fast feedback loop, we quickly hit limitations that made this solution unreliable, hard to maintain, and no longer compatible when DoorDash moved to a multi-cluster architecture.
To address the limitations of the existing fast-feedback-loop solution, we used Signadot and multi-tenancy to build a new solution. In addition to offering new features, the new solution is safe, highly reliable, easy to maintain, and compatible with a multi-cluster architecture. These advantages improved developer velocity, software reliability, and production safety.
Standard Kubernetes port-forward is unsafe and unreliable for product development
Kubernetes port-forward is a mechanism that provides access to an application running in a cluster from a developer workstation. Once the port-forward command is run, requests sent to a local port are automatically forwarded to a port inside a Kubernetes pod. Using port-forward, a service running locally can connect to its upstream dependencies. This way developers can execute requests against the service running locally to get fast feedback without the need for building, pushing docker images, or deploying them in the Kubernetes cluster.
Kubernetes port-forward is not safe and reliable for product development for the following reasons:
- Port-forward requires maintaining API keys in developer workstations. At DoorDash, clients need to pass an API key in the protocol headers for authentication against the services. This creates a big hurdle in connecting to upstream dependencies because developers don’t have those API keys in their workstations. It is cumbersome for each developer to provision and maintain API keys.
- Port-forward makes it difficult to restrict API endpoint access. Because port-forward RBAC gives access at the namespace level, it is not possible to build production guardrails such as restricting certain API endpoints.
- Port-forward requires building and maintaining ad-hoc scripts for each service. Because each service has different upstream dependencies, port-forward requires picking local ports for each one. This requires each developer to ensure that the port numbers are unused and do not conflict with each other. These extra steps make the port-forward hard to build and maintain.
- Kubernetes pod failures or restarts make port-forward unreliable. There is no auto-connect feature to cover failure scenarios where the connection is killed or closed by the upstream service. Additionally, port-forward’s unreliability is enhanced because it works at the pod level, but Kubernetes pods are not persistent.
- Port-forward doesn’t support advanced testing strategies, including routing test traffic to workstations. Given the one-way nature of port-forward, it only supports sending requests to the upstream services. But developers want to send test traffic through the front-end and receive requests on their workstation that were intended for a specific service.
- Port-forward is not compatible with a multi-cluster architecture. DoorDash’s move to a multi-cluster architecture highlighted Kubernetes’ incompatibility. Services don’t necessarily stay in one cluster in a multi-cluster architecture, requiring that service discovery be built on top of port-forward.
For these reasons, we quickly hit limitations that made the port-forward-based solution unreliable and hard to maintain. While other well-known solutions such as kubefwd are similar to port-forward and resolve some of these issues, they don’t address the security features we need to enable safe product development in a production environment.
Signadot and multi-tenancy combine for a fast feedback loop
Signadot is a Kubernetes-based platform that scales testing for engineering teams building microservice-based applications. The Signadot platform enables the creation of ephemeral environments that support isolation using request-based routing. Signadot’s connect feature is built on the platform to enable two-way connectivity from developer workstations and to or from remote Kubernetes clusters.
We leveraged Signadot’s connect feature to connect locally running services to those running in the Kubernetes cluster without changing any configuration. Signadot also supports receiving incoming requests from the cluster to the locally running services.
How the connect feature works
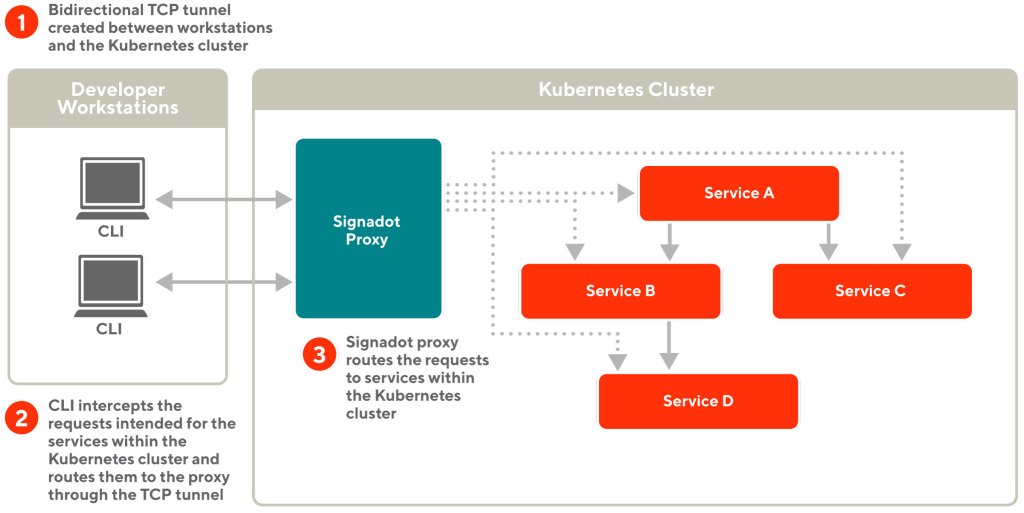
Signadot provides a CLI component running on the developer workstation and a proxy component running on the Kubernetes cluster. The connect feature works as follows, which is also illustrated in Figure 2:
- Using the CLI component, a developer creates a TCP tunnel and connects to the proxy component running within the Kubernetes cluster.
- The proxy component sends back all the Kubernetes services identified by the cluster DNS to the developer’s workstation.
- The CLI component automatically resolves DNS and proxies network traffic intended for the Kubernetes cluster via the TCP tunnel.
- The TCP tunnel also allows locally running services to receive requests from the Kubernetes cluster.
Signadot improves local development significantly when compared with Kubernetes port-forwarding for several reasons, outlined here and in Figure 3:
- Signadot’s connect feature works without the need for complex port-forward scripts. Developers don’t need to write and maintain the custom port-forward scripts for each service, reducing friction and easing maintenance. Running the Signadot daemon on a developer workstation through the CLI is sufficient to reach services within the cluster.
- Signadot’s connect feature is agnostic to Kubernetes pod failures or restarts. Signadot proxy automatically refreshes the service endpoint information and pushes it to the developer workstation, so any pod failures or restarts won’t impact product development.
- Signadot provides pluggable functionality to add custom guardrails at the request level. Signadot provides a feature to write envoy filters for the proxy component. The envoy filters help inspect the requests and apply custom rules based on the request data.
- Signadot supports advanced testing strategies when developers want to route test traffic to their workstations. Using the bidirectional tunnel with the cluster, Signadot provides support to route test traffic to developer workstations through integration with Istio or custom SDKs.
- Signadot provides functionality to integrate with multi-cluster environments.
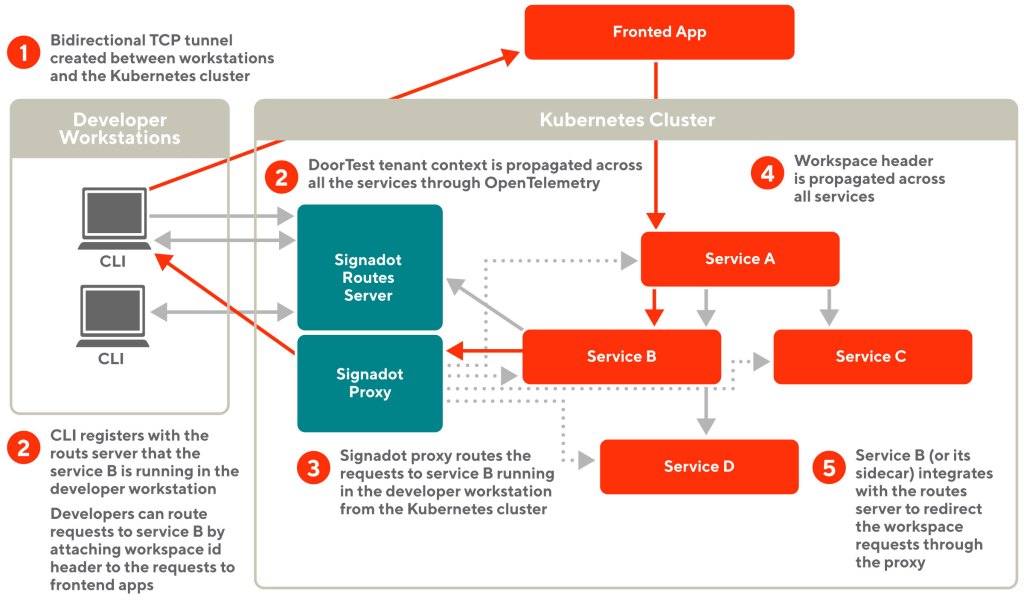
In the example shown in figure 3 above, the developer starts service B’ in their workstation and registers a workspace with the routes server using the CLI. The developer then browses the frontend application with the workspace information injected. The requests hit service B (or its sidecar) and then get routed back to service B’ through the Signadot proxy and the bidirectional tunnel.
The need for multi-tenancy to build production guardrails
We need to provide safeguards to ensure against developers intentionally or accidentally accessing sensitive production data when using the fast feedback loop. To achieve this, we adopted a multi-tenancy model and added safeguards in the Signadot proxy so developers can only access test data.
Multi-tenancy is an architecture paradigm in which one software application and its supporting infrastructure are designed to serve multiple customer segments, also called tenants. We addressed the safeguards challenge in the fast feedback loop by adopting the multi-tenancy model and introducing a new tenant named DoorTest in the production environment. The multi-tenancy model enabled us to easily isolate test data and customize software behavior for the DoorTest tenant as explained in our earlier blog post.
In this multi-tenant model, all services identify the tenancy of the incoming requests using a common header called tenant ID. This header is propagated across all our services through OpenTelemetry, enabling our services to isolate users and data across tenants.
Now that we have a test tenancy created using the multi-tenancy mode, we use Signadot envoy filters to build custom rules that ensure requests only operate in the test tenancy by inspecting the header tenant ID.
Leveraging Signadot envoy filters to build production guardrails
Signadot provides a feature to write envoy filters for the proxy component. Envoy filters help inspect requests going through the proxy, optionally changing the request or response data. Using envoy filters, we build a custom rule that ensures requests only operate in the test tenancy by inspecting the header tenant ID.
Using the envoy filters’ mechanism, we build a custom rule to automatically inject upstream service API keys to the outgoing requests. This way our developers don’t need to configure or maintain the API keys in the developer workstations, as shown in Figure 4.
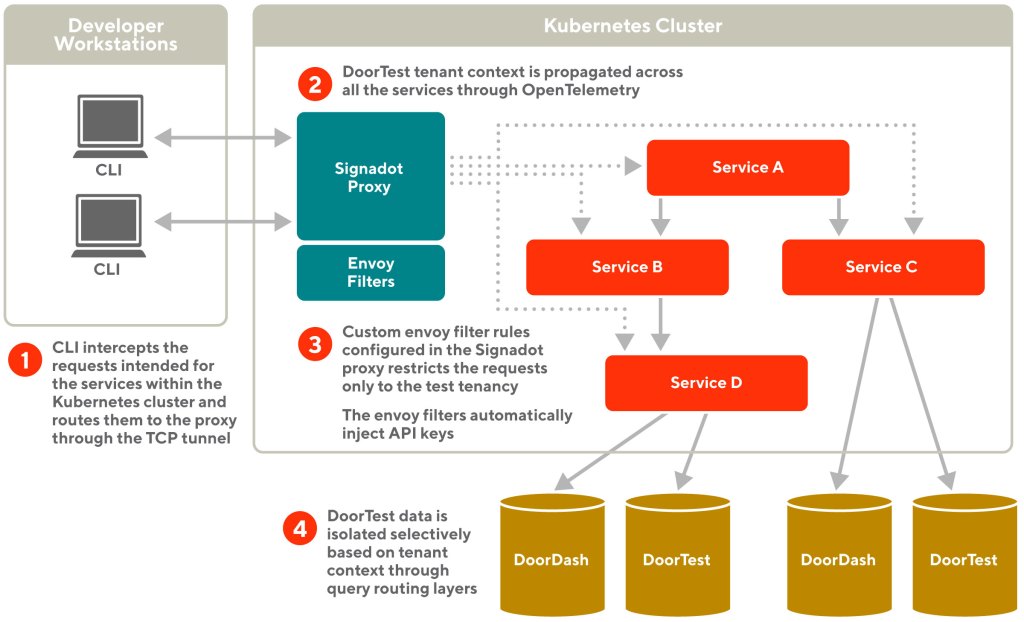
This feature provided us with much-needed flexibility to build new guardrails for the fast feedback loop.
Supporting multi-cluster architecture
After establishing the fast feedback loop with a single Kubernetes cluster, we had to upgrade our Signadot proxy server to support our multi-cluster architecture. Previously, all services were running under one Kubernetes cluster. We adopted a multi-cluster architecture to improve system reliability, which means that services are running across multiple Kubernetes clusters.
In this model, the developer sending a request needs only to know the global URL for the service, not which cluster to use. When a developer requests a service’s global URL, Signadot CLI and the proxy server forward the request to the service’s internal router. Then the internal router dispatches the request to the cluster in which the service is running.
We were limited to routing traffic inside a single cluster with the port-forwarding-based approach and initial Signadot solution. We could not route traffic running in newly introduced clusters. As more services move to the multi-cluster model, we upgraded Signadot so that developers can test out various scenarios.
Figure 5 shows the upgraded Signadot architecture and how each request from the local machine is propagated from one cluster to another.
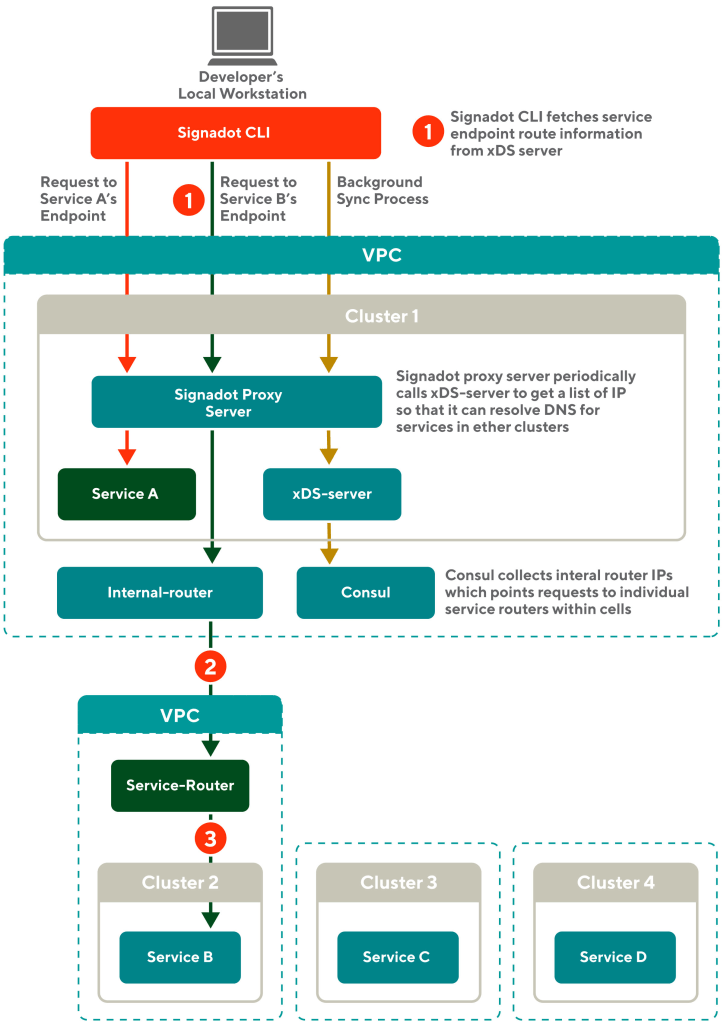
The red arrows in Figure 5 show the previous request flow within Cluster 1, which works in the prior version of Signadot.
Caramel colored arrows in Figure 5 shows how our network infrastructure synchronizes necessary information in the background. To resolve DNS for services running in different clusters, we use the xDS-server and Consul. The Consul monitors all the clusters and gathers lists of IPs for each service. The xDS-server must live in Cluster 1 to provide an API endpoint for the Signadot proxy server. For services in Cluster 1, the IP list will resolve to the actual pod IPs that are deployed in Cluster 1. The IP list for services in other clusters is resolved to an internal router.
When the request comes to the internal router, it routes the traffic to the service router that will then forward the request to the target cluster.
The Signadot proxy server periodically pulls the IP lists for all services from the xDS-server endpoint. Once a developer runs Signadot CLI on their local machine, the CLI pulls the IP lists from the Signadot proxy server and stores one IP for each service in the local/etc/hosts file.
Now developers can send requests to any service across multiple clusters from their local workstations. This efficient design negates concern about local requests overwhelming the internal DNS server.
Blue arrows in the diagram show how our system propagates a request from the local workstation to Cluster 2:
- A developer’s local workstation connects to Cluster 1 and runs Signadot CLI. A developer sends requests to service B’s endpoint with its global URL. At this point, the local workstation knows the IP of the internal router. The local workstation makes a request to service B with one of the IPs. The request is sent to the Signadot proxy server in Cluster 1 through a TCP tunnel made by the Signadot CLI.
- Then the Signadot proxy server routes the request to an internal router. The router is implemented using an Envoy proxy.
- The internal router then routes the traffic to a service router.
- The service router ultimately forwards the request to service B running inside Cluster 2, successfully completing a developer’s request to service B.
In this example, a developer is sending a request through Cluster 1. Note that developers can choose which cluster to connect to and therefore can send requests through any cluster. Now developers can test their local code by connecting to dependencies in any cluster.
Other alternative solutions we considered
We considered Telepresence, which provides a fast feedback loop similar to the one discussed in this post. While it is a great solution, we decided to use Signadot because:
- Telepresence requires the use of its sidecar for intercepting requests and routing them to developer workstations. This sidecar conflicts with our compute infrastructure where we built a custom service mesh solution using envoy sidecars. So we decided to leverage Signadot SDKs to build the intercepting mechanism in our custom service mesh solution.
- We needed guardrails applied to the requests originating from the developer workstations, but Telepresence lacks that capability.
- We integrated Signadot with an internal xDS-server to support multi-cluster architecture, another capability that Telepresence lacks.
One other alternative would be to move development to remote workstations. While this is a viable idea, we decided to pursue the solution we describe here because:
- Building remote development is costly because it requires extra hardware.
- Building remote development is time-consuming because of the need for multiple integrations with our environment.
Even with remote workstations, we still need the same production guardrails through tenancy and support for multi-cluster architecture as discussed earlier. Using Signadot has helped us reap benefits quickly while providing the flexibility to reuse the same building blocks for future remote development solutions.
Conclusion
Many development teams are slowed down by unreliable or slow feedback loops. The Signadot and multi-tenancy solution we describe here is suitable for companies that are growing very rapidly and need to develop product features quickly with high reliability.
Our new fast feedback loop has increased developer velocity by reducing the time to deploy code to the Kubernetes cluster more frequently; increased reliability because developers can easily test their code during the development phase, and boosted production safety through standardization and guardrails.