
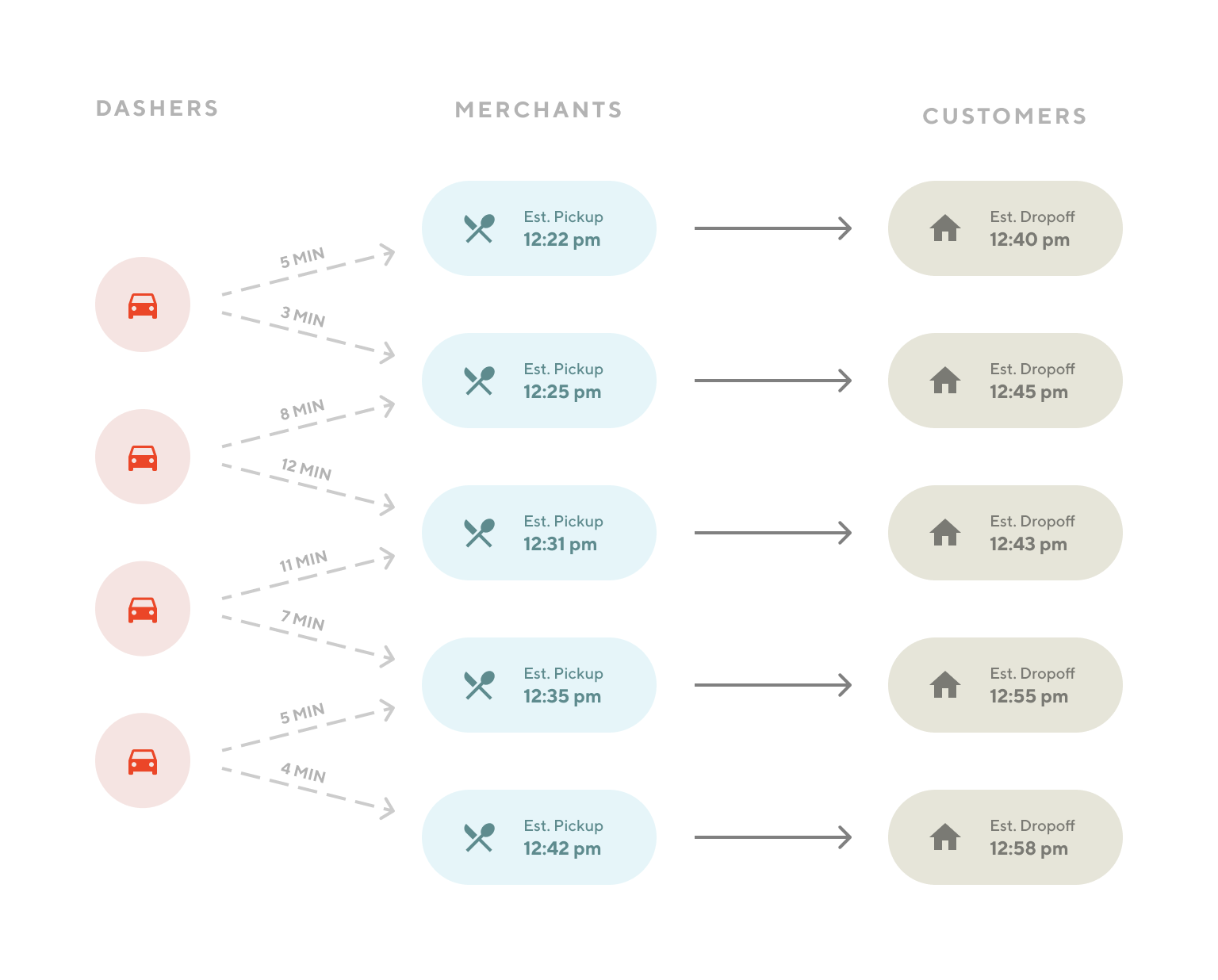
DoorDash is a dynamic logistics marketplace that serves three groups of customers:
- Merchant partners who prepare food or other deliverables,
- Dashers who carry the deliverables to their destinations,
- Consumers who savor a freshly prepared meal from a local restaurant or a bag of groceries from their local grocery store.
For such a real-time platform as DoorDash, just-in-time insights from data generated on-the-fly by the participants of the marketplace is inherently useful to making better decisions for all of our customers. Our company has a hardworking group of engineers and data scientists tackling interesting prediction problems like estimating food preparation time or forecasting demand from customers and supply from our merchants and dashers.
We have already been using insights from aggregations of historical data over a month, a week, or even a day ago for these problems, which gives us very important wins. However, up-to-date knowledge from real-time events about the marketplace turns out to be quite useful in order to react to the ever-evolving nature of the communities that we serve.
For example, a famous burrito place on Market Street in San Francisco may usually take 10 mins to prepare a burrito. However, when it sees a huge influx of orders on the national burrito day, it may start taking longer to prepare the burrito. In order to accurately predict the preparation time in the near future, it is useful to have an idea of the “number of orders received by the store in the last X minutes”.
Like many resilient engineering systems, DoorDash has a collection of services that isolate their responsibilities and interact with each other to orchestrate the logistics marketplace. These systems range from order submission and transmission, to delivery assignment, to planning delivery routes, to batching orders.
We wanted to collect truly real-time stats from several of these services, hence, we needed a cross-cutting engineering system that can collect business level events from core services, match events from potentially multiple sources, aggregate them in a stateful manner and publish the time-windowed aggregations for ML models to use.
We made design choices that simplified the creation of a features pipeline. Some essential pillars of the real-time feature pipeline design are:
- Standardize business events as they happen on a timeline. It not only simplifies the definition of those events, but also keeps them self-contained, without any complicated relationships to other parts of the business.
- Use a distributed log to publish and subscribe to the business events. This choice helps deploy and scale producer services independent of each other. Also, the aggregator service can independently follow maintenance schedules without fear of losing the events that are being published.
- Use a distributed and stateful stream processing framework that can consume events published onto the distributed log and continuously run time-windowed aggregations on those events to produce aggregated features.
- Use a fast and distributed in-memory cache for storing the statefully aggregated features. The resilience of such a cache makes certain that ML predictors can access the features independent of who published them and when it was published.
In order to build the right solution, we needed to make technology choices that we feel confident about, evolving with the needs for our engineering organization in the future.
We chose protobuf to define the schema of events that can be versioned, have their changes tracked, are both forward and backward compatible with changes, and have their corresponding Java / Python objects published in a central library for access by producer and consumer services.
An example of a light-weight event looks like the following:

As is evident, one of the events that a store entity in DoorDash’s application domain can generate is “an order o was confirmed by a store s at timestamp t.” When we are interested in more business events related to the store’s timeline, we can add another object with only the detail specific to it. In this case the StoreOrderConfirmedData event only has an order_id associated with it.
We chose Apache Kafka as the common distributed log for transporting business events from their producers to the stateful streaming aggregator. Kafka with its `topics` semantics makes it easier to segregate business events based on the entities for which the events are generated. Also, partitioned topics are essential to keeping time-windowed aggregations for the same key local to a single compute node, thus reducing unnecessary shuffling of data in real-time.
Most importantly, we used Apache Flink for its stateful stream processing engine and simple time-windowed aggregation semantics, abstracted as the DataStream API. To operationalize Flink, we had a choice between the normal deployment environment of Docker and Kubernetes on AWS, like any other service at DoorDash, or a Flink deployment over a map-reduce cluster sitting behind a resource manager, or to go the route of a fully managed offering like Flink on AWS. To keep things consistent in deployment strategy with the rest of the services at DoorDash, we chose to launch JobManager and TaskManager instances on Kubernetes to create a “job cluster”, without the need for a full fledged resource manager like Apache Yarn. With that lightweight cluster dedicated to aggregating real-time features, we roll out updates to the Flink application with a normal service deployment, rather than submitting a new job to a “session cluster”. The Data Infra team at DoorDash is building a far and wide reaching Real-time infrastructure, which will allow real-time features to become a general citizen of that ecosystem. More on that to come.
And finally, we used Redis as the distributed, in-memory store for hosting ML features. We follow a descriptive naming convention to unambiguously identify what a feature is and which entity it is about. Keeping universally consistent feature names allows several ML models to consume from a pool of features. For example, the count of orders in the last 20 minutes for a restaurant with store_id 123 is ‘saf_st_p20mi_order_count_sum.st_123’. It can be used by a ML model estimating food preparation time, or another model forecasting store demand in the future. DoorDash’s ML applications are trained and served through a common predictions library that uses features from this Feature Store. For those interested, we soon plan to publish further blog posts on our prediction service, feature engineering, and other components of the ML infrastructure.
We have settled on Kotlin as our primary language of choice as a company, for building expressive, powerful systems that scale. Writing aggregation logic against Java bindings of the DataStream API from Flink in Kotlin was seamless.

We started noticing the impact from real-time features on the performance of our products in the following areas:
1. Delivery ETA for the consumer:

When a consumer decides to place an order on DoorDash, we display an ETA on the checkout page. This is our best estimate of how long it will take the food to arrive and represents the promise we make to the consumer. Since the marketplaces we operate in are extremely dynamic, it can be difficult to get accurate ETAs — especially during lunch and dinner peaks when a large delivery order or a large party eating in at the restaurant can significantly back up the kitchen and delay subsequent orders.
For situations like this, the addition of real-time information has contributed significantly to the ability of our models to react swiftly and provide more accurate expectations to our customers. To create these ETAs, we use a gradient-boosting algorithm with dozens of features, and the real-time signal on dasher wait at the restaurant and number of orders placed are among the top 10 most important. As seen in the graph below, the addition of real-time signal allows our ETA predictions to align much more closely with actual delivery times.

2. Estimating order preparation time:
In order to match the right dasher with the right delivery, the assignments platform needs to have an estimate for when an order is expected to be ready for pick up at a restaurant. If we underestimate and have the dasher show up earlier at the restaurant, for example, we risk having the dasher wait longer; if we overestimate and have the dasher arrive at the restaurant later, we delay the delivery, with consequences like the meal getting cold. Thus, the estimate influences both quality and efficiency of the fulfillment. We iterated on improving the underlying model for estimating order preparation time, with previously available historical features, and ended up with a model that performed better. However, the estimation error is higher on holidays as seen below:

Part of the problem arises because holidays do not occur frequently in the training data and the model/underlying feature set is not responsive to the dynamics of holidays. We engineered some real time features that capture the changes in marketplace conditions more dynamically and were able to mitigate the issue of high prediction inaccuracy.
We have only begun to scratch the surface with what is possible from using real-time insights from the marketplace to better inform our decisions, and better serve our customers. If you are passionate about building ML applications that impact the lives of millions of merchants, dashers, and customers in a positive way, do consider joining us.
Acknowledgements:
Param Reddy, Carlos Herrera, Patrick Rogers, Mike Demmitt, Li Peng, Raghav Ramesh, Alok Gupta, Jared Bauman, Sudhir Tonse, Nikihil Patil, Matan Amir, and Allen Wang










 Coming to America
Coming to America






