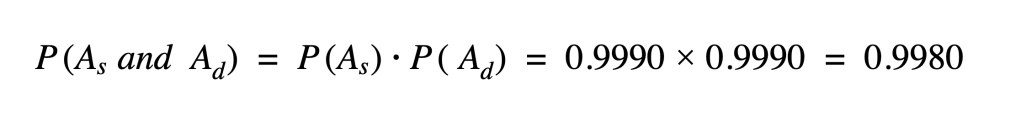Understanding the contents of a large digital catalog is a significant challenge for online businesses, but this challenge can be addressed using self-supervised neural network models. Product discovery in particular becomes difficult when a digital catalog gets to a size that is too large to manually label or analyze.
For DoorDash, having a deep understanding of our catalog can help with product recommendation, search, promotional campaigns, and operational intelligence. While we worked in the past on building a human in the loop system to tag our items, we need a generalizable way of associating items in a semantically meaningful way to power machine learning use cases.
In this article we describe an approach to train high-quality generalizable embeddings by using techniques in self-supervised learning on our internal search data. We also discuss trade-offs with alternative methodologies and go over the details of the model training and evaluation process for our selected solution.
The problem with a large, growing online catalog
The DoorDash catalog is extremely large and constantly getting larger as we add new partners and verticals. As ML powers more core aspects of DoorDash’s platform, we need to provide a way for teams to be able to process the catalog without building bespoke models. Note that unlike our previous discussion around tagging, which was focused on human-interpretable labels for the catalog, here our goal is to develop a representation of the items in the catalog that can be used by ML systems to fulfill many use cases.
Understanding the contents of the catalog is important in order to operate the business and power many consumer-facing and internal applications such as:
- Recommendations of new stores based on consumers’ known preferences
- Recommending items to a consumer when they interact with a new store
- Retrieving relevant stores and items for a search query
- Automatically suggesting promotions for stores similar to a consumer’s recent order history
- Understanding what kinds of items consumers purchase after a search
The above use cases span multiple separate teams at DoorDash, but we need to find a common way to represent items in the catalog that is usable by all teams.
How to represent items in the catalog
One way to formalize the problem is to think about how we can represent items in the catalog in a manner that preserves good metric properties, meaning that similar items should have similar representations. A natural representation in this case would be to use embeddings that preserve intuitive relationships between items. For example, we would expect “tacos” and “burritos” to be more similar to each other than to “pad thai” because the former are both Mexican foods and pad thai is Asian food.

In a search retrieval context, we also want to be able to create a query embedding which can be compared to item and store embeddings in order to retrieve the most relevant results. Our model needs to embed both queries and items into the same latent space (Figure 1) in order to make them comparable. For example, once we have embeddings for the query “mexican” and item “taco” we would be able to measure the cosine similarity between the query embedding and item embedding to know that “taco” is a relevant result.
We can also easily build embeddings that capture store cuisine types and consumer preferences by treating stores and consumers as bags of item embeddings. This method keeps the store and consumer embeddings in the same latent space, and thus comparable to items. This allows us to use our embeddings to include catalog knowledge to store recommendation and personalization models.

The main challenge we have to solve is how to use our limited labeled data to effectively train embeddings on possibly very rare classes. Our solution was to train embeddings by leveraging self-supervised methods on DoorDash’s large volume of search. However, we’ll review some of the more traditional techniques to train embeddings to understand why they don’t work for our problem.
A review of standard techniques to build embeddings
There are several standard approaches to training embeddings that do not work well for our use case. Traditional approaches include Word2vec training on item IDs or training deep learning classifiers and taking the output of the last linear layer. More recently, it has also become common in natural language processing (NLP) to finetune a large pre-trained model like BERT. However, for DoorDash’s problem of large, sparse catalogs that are continuously evolving, these methods have a few disadvantages:
Alternative 1: Word2vec embeddings on entity IDs
Word2vec embeddings can be trained on any set of entity IDs using customer behavior such as views or purchases. These embeddings learn the relationships between IDs by assuming that entities a customer interacts with in the same session are related to each other, similarly to the Word2vec distributional hypothesis. In fact, at DoorDash we already train these kinds of embeddings regularly for stores and consumers to use in recommendations and other personalization applications. See Figure 3 for an example architecture for this on item IDs.

However, Word2vec embeddings suffer from some drawbacks for the purpose of preserving semantic similarity for a large catalog. First, they require regular retraining as new entities get added to the catalog. Because millions of items are added daily, retraining these embeddings daily is computationally expensive. Furthermore, embeddings trained using this method are prone to suffering from sparsity issues, because IDs that customers interact with infrequently do not get trained well.
Alternative 2: Embeddings from deep neural networks trained on a supervised task
It has been observed empirically that deep neural networks that have low training error on classification tasks can learn high quality representations of the target classes. The output of the last hidden layer of the network can then be treated as an embedding of the original input. With a diverse and large high quality labeled dataset this approach can be very effective at learning high quality embeddings to reuse for classification tasks.

However, this method of training does not always guarantee good metric properties for the underlying embeddings. Because our priority is ease-of-use for downstream applications, we’d like these embeddings to be easily comparable using simple metrics like cosine similarity. Due to this method being supervised, the quality of the learned metric depends heavily on the quality of the annotated training set. We need to ensure that the dataset has hard negative samples to ensure that the model can learn to discriminate between closely related labels. This problem is especially exacerbated for rare classes that will have limited data samples. Our described solution will circumvent this issue by automatically generating samples from an unlabeled data and learning a representation for the label.
Alternative 3: Fine tuning a pre-trained language model such as BERT
With recent advances in training large models in NLP on large corpora, it has become popular to fine tune these models to learn embeddings for a specialized task via transfer learning (see Figure 5 for a sample architecture). A popular pre-trained model is BERT and this approach can be straightforwardly implemented using popular open source libraries. This approach can often overcome the problem of data sparsity and for general NLP problems provides a very strong baseline.

While BERT embeddings are a significant improvement on the baseline, it suffers from slow training inference time due to model size. Even using a distilled model such as DistilBERT or ELECTRA can be much slower than custom models which are much smaller. We’ve also observed that with enough domain-specific data, even if it is unlabeled, self-supervised methods have substantially better metric properties for our task compared to pre-trained language models.
Our solution: using self-supervised learning to train embeddings
After eliminating the above approaches we went with self-supervised methods to train embeddings based on the item name and search query. By using subword information, such as character-level information, these embeddings can also be generalized to text that was unseen in the training data.
In order to ensure good metric properties, we use a Siamese Neural Network ( also called a Twin network) architecture with triplet loss. The triplet loss attempts to force similar examples together and push dissimilar examples apart in the latent space. We use Twin networks to ensure that the encoders used for query and item text both embed into the same latent space in a way that preserves distances between similar examples.
Constructing a dataset
In order to train with a triplet loss we need a dataset with the structure <anchor, positive example, negative example>. For our problem we define the anchor as the raw query text and we consider “relevant” and “irrelevant” for the query as positive and negative samples respectively.
To construct this dataset (see Figure 6 for a sample), we need to develop a set of heuristics to formulate the training task. The following heuristics were used to determine relevant and irrelevant items which correspond to a positive and negative training sample respectively:
- An item X is relevant for a query Q, if a user searched for query Q and immediately purchased X afterwards in the same session and X is the most expensive item in the basket
This heuristic for positive samples ensures that we only take the main item in a cart, which we assume is likely the most relevant
- An item X is irrelevant for query Q, if X was purchased in a query R where the Levenshtein distance of Q and R is > 5
This heuristic for negative samples guarantees that items purchased for similar queries (e.g., “burger” and “burgers”) are not treated as irrelevant. Note that generating hard negative samples can be crucial for preventing mode collapse. In our case we noticed even this simple heuristic and natural variation in the text was sufficient for training. In the future we hope to investigate more sophisticated mining techniques.

Furthermore, we did minimal normalization on the inputs, only lower casing all strings and removing punctuation. This allows the trained model to learn to become adaptable to spelling errors and other natural variations in language.
| Raw input | Processed input |
| Chicken Burrito | [‘chi’, cke’, ‘n b’, ‘urr’, ‘ito’] |
| Burger + salad | [bur’, ‘ger’, ‘ sa’, ‘lad’] |
In order to ensure our model can generalize to samples with out-of-vocabulary tokens, we used character trigram sequences to process the inputs (Figure 7). We experimented with multiple alternative tokenization schemes (word ngram, bytepair encoding, WordPiece, and word + character ngrams) but found trigrams had similar or superior predictive performance and could be trained more quickly. We also found that by using a bidirectional LSTM to process our inputs in the encoder layer, we removed most of the need for sophisticated tokenization.
Laying out the model’s architecture
The model is a Siamese network (Figure 8) that uses encoders composed of deep neural networks and a final linear layer that outputs the embeddings. All weights are shared between encoders. Because the weights are shared between encoders, we ensure that the encodings for all heads go into the same latent space. The outputs of the encoders are then used to calculate a triplet loss.

A triplet loss (with margin) is defined as:
L(a, p, n, margin) = max(d(a, p) -d(a, n) + margin, 0)
Where a is the anchor, p is the positive sample, n is the negative sample, and d is some distance function (typically taken to be euclidean distance).

Intuitively, minimizing this loss brings positive samples closer to the anchor and pushes negative samples further away from the anchor (Figure 9).
class SiameseNetwork(torch.nn.Module):
def __init__(self, learning_rate, transforms, model, **kwargs):
super().__init__()
self.learning_rate = learning_rate
self.transforms = transforms
self._encoder = model(**kwargs)
self.loss = torch.nn.TripletMarginLoss(margin=1.0, p=2)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.learning_rate)
def _loss(self, anchor, pos, neg):
return self.loss(anchor, pos, neg)
def forward(self, anchor, seq1, seq2):
anchor = self._encoder(anchor)
emb1 = self._encoder(seq1)
emb2 = self._encoder(seq2)
return anchor, emb1, emb2

The encoder (Figure 11) is a bidirectional LSTM followed by a feed-forward network as a projection head. We find that using a feed forward network with ReLU units adds additional modeling power. We take the output of the final layer of the projection head (represented here separately as a linear layer) as our final embedding which is used to compute the loss.
class LSTMEncoder(torch.nn.Module):
def __init__(self, output_dim, n_layers=1, vocab_size=None, embedding_dim=None, embeddings=None, bidirectional=False, freeze=True, dropout=0.1):
super().__init__()
if embeddings is None:
self.embedding = torch.nn.Embedding(vocab_size, embedding_dim)
else:
_, embedding_dim = embeddings.shape
self.embedding = torch.nn.Embedding.from_pretrained(embeddings=embeddings, padding_idx=0, freeze=freeze)
self.lstm = torch.nn.LSTM(embedding_dim, output_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
self.directions = 2 if bidirectional else 1
self._projection = torch.nn.Sequential(
torch.nn.Dropout(dropout),
torch.nn.Linear(output_dim * self.directions, output_dim),
torch.nn.BatchNorm1d(output_dim),
torch.nn.ReLU(),
torch.nn.Linear(output_dim, output_dim),
torch.nn.BatchNorm1d(output_dim),
torch.nn.ReLU(),
torch.nn.Linear(output_dim, output_dim, bias=False),
)
def forward(self, x):
embedded = self.embedding(x) # [batch size, sent len, emb dim]
output, (hidden, cell) = self.lstm(embedded)
hidden = einops.rearrange(hidden, '(layer dir) b c -> layer b (dir c)', dir=self.directions)
return self._projection(hidden[-1])

There are also alternative approaches to self-supervised learning we have explored, such as contrastive learning, but we found the sensitivity to batch size led to unstable training. We’ll continue to explore more alternatives in this space, as this is a fast-advancing area in ML research with significant successes in computer vision. Other methods amenable to large datasets with limited labels such as GraphSAGE are also alternatives we are currently exploring to train embeddings that better incorporate customer behavior.
Model performance evaluation
We evaluate the model according to both qualitative metrics like evaluation of an embedding UMAP projection and quantitative metrics such as F1-score on a baseline.
We evaluated qualitative results by looking at UMAP projections for the embeddings (Figure 13). In particular we can see that similar classes are projected near each other, meaning that the embeddings capture semantic similarity well.

Given the promising results of the qualitative evaluation, we also did a more rigorous benchmarking of the model on some baseline classification tasks to understand the quality of the embeddings as well as potential gains from using them in other internal models.
| Model type | Performance |
| FastText Baseline | – |
| LSTM Classifier (cross-entropy loss) | +15% |
| Siamese Neural Network | +23% |
In terms of quantitative metrics, our model improved over an F1-score baseline (a FastText classifier trained on trained class labels) by ~23%. This is a substantial gain, especially since the Siamese neural network is evaluated on a zero-shot classification task and the baseline is trained on labeled data.
Furthermore, we also noticed that using these embeddings as features for downstream classification tasks leads to significant improvements in sample efficiency. While training tagging models, we observed a need for greater than three times the existing labeled data to train comparably accurate models using a FastText classifier. This suggests that the learned representations carry substantial information about the content of the text.
Given the substantial improvement in both F1 performance and sample efficiency when using these embeddings in classification tasks, we’ve begun to deploy the embeddings as features available for consumption by other models at DoorDash.
A walkthrough of a sample application enabled by catalog embeddings
Here we’ll describe one simple application of these embeddings to give an example of the new product use cases we can enable via catalog embeddings.
In order to improve content recommendations to consumers, we would like to programmatically generate carousels based on the user’s most recent orders. For example, if a consumer has recently ordered from “Papa John’s Pizza” other fast food pizza chains might be a good recommendation. To populate this carousel we want to retrieve stores which are similar to the store the consumer most recently purchased from.
Without embeddings we would need to build a dedicated model that takes into account <consumer_id, last_store_id> and attempts to predict the probability of conversion on every candidate store_id. With embeddings we can instead use a two stage process:
- Use a filtering step to retrieve the stores most similar to last_store_id
- Do a personalized ranking of filtered candidates for each consumer, using a pre-existing ranker.
Because computing the filter is fast via cosine similarity and we do not need to collect any data for the dedicated ranker, this process is relatively fast and simple to implement. See Figure 14 for more details on this process. Also note that generating a semantically similar store is straightforward by averaging the item embeddings on each store’s menu and can be done in a batch process to reduce real-time system load.

The effort needed to train a dedicated ranker is substantially higher than using this kind of pre-computed embedding. We can iterate much faster on product ideas like this and prove their impact on the user experience prior to investing in dedicated rankers. Furthermore, these embeddings can be used directly as model inputs to improve recommendations.
Conclusion
Above we have discussed the problem of training item embeddings that preserve semantically meaningful relationships. With these embeddings we have immediately unlocked opportunities that are otherwise time-consuming and expensive to support.
These types of embeddings and self-supervised methods in general are especially helpful to develop immediately re-usable ML products at companies with fast-growing catalogs. While other ML approaches might be more suitable for specialized tasks or with less automatically generated text, we’ve found self-supervised embeddings still can add strong baseline performance to tasks requiring high quality representations of text data. We also observe that generally domain-specific embeddings work better for internal applications such as search and recommendations compared to off-the-shelf embeddings like FastText or BERT.
We have already begun to test and deploy these embeddings across multiple surfaces in recommendations and programmatic merchandising. For these use cases, we have seen immediate substantial improvements in the performance of models using these embeddings and we’re looking to deploy them in more applications.
Further Reading
[1] Siamese Neural Networks for One-shot Image Recognition. https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
[2] A Simple Framework for Contrastive Learning of Visual Representations. https://www.cs.toronto.edu/~hinton/absps/simclr.pdf
[3] Deep Metric Learning with Triplet Loss. https://arxiv.org/pdf/1412.6622.pdf
[4] FaceNet: A Unified Embedding for Face Recognition and Clustering. https://arxiv.org/pdf/1503.03832.pdf