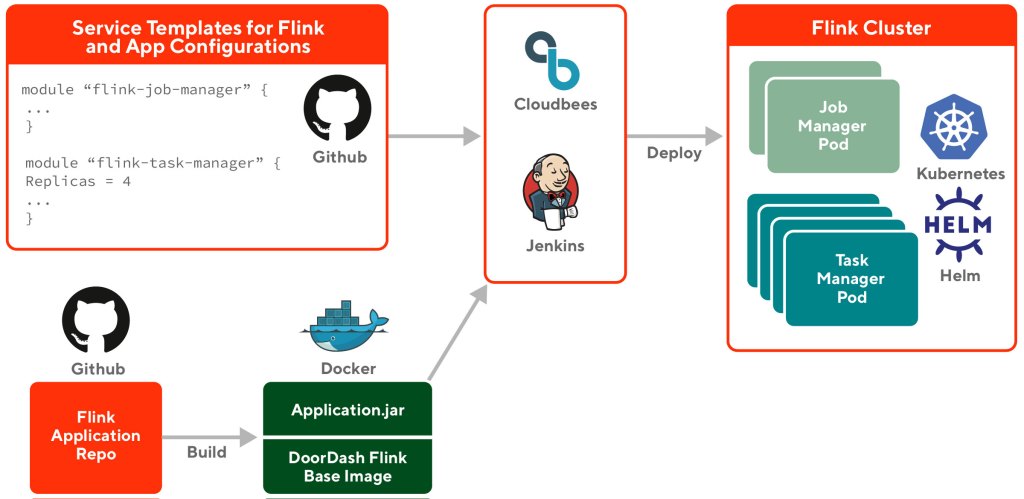
A topic of great debate among many engineers is whether or not SwiftUI is ready for enterprise. It’s no secret that DoorDash has fully embraced it in our Consumer app, as we recently held a technical meetup to share many of the challenges we’ve overcome. Our biggest challenge, however, has been dedicating enough time to rewrite multiple applications in parallel.
Starting with iOS 13, Apple offered a drastically different UI paradigm in the form of SwiftUI. It was a major departure from UIKit with reactive data pipelines and a declarative syntax. Many enterprise codebases are driven by a one-way data flow (e.g. VIPER, MVVM-C), whereas SwiftUI takes advantage of two-way data flow in the form of bindings and observables.
Our team saw a unique opportunity to build new features with SwiftUI, while isolating them within our existing VIPER architecture. This bottom-up approach would allow for incremental improvements and prove less disruptive to other developers. It also had the added benefit of being completely agnostic to the rest of the codebase; other features would continue to use the established VIPER interface, never requiring knowledge about implementation details of the View layer.
Why adopt SwiftUI with a bottom-up approach?
Adopting SwiftUI with a bottom-up approach is better because it minimizes risk by being less disruptive, while allowing for incremental improvements.
Introducing a new UI paradigm would be a considerable risk for an established application like Dasher, which is used by delivery drivers to accept and carry out food order offers. Forcing other teams to change the way they work would considerably lengthen development times. Therefore, adopting SwiftUI with a top-down approach was out of the question. DoorDash elected to rewrite the Consumer app last year, which we estimated would take thousands of engineering hours to complete. Our bottom-up approach would mitigate the impact to other teams by working within the existing module-level boundaries. Working within these constraints allowed us to use SwiftUI for new modules without requiring changes to the existing code.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Mitigating the challenges of embracing new technologies
Adopting cutting-edge features is not a new problem. There are always new trends and features being introduced, and engineers are always looking to try them out. Companies typically take one of two approaches.
Top-down
A top-down approach involves throwing out, or rewriting the entire application in favor of new code with the latest technology. There are many great reasons to take this route. One of the most significant is that it avoids migrating legacy code. Often this code would have been written by people who have left the company, or may have required special knowledge of how portions of the application worked. Many hundreds of engineering hours worth of effort can often be spent on maintaining legacy code. This effort is no longer required in a rewrite. Starting with a clean slate allows for consistent patterns and references in the codebase, rather than having multiple ways to achieve the same result.
New developers will often look for examples when building new features. If a technology is partially adopted, as it would be in a bottom-up approach, there may be more than one way to achieve the same result, which can lead to uncertainty. There’s also the added benefit of appealing to engineers’ love of the “new and shiny”, which can be great for hiring and morale. It can be off-putting to hear that companies are using older technologies during the interview process.
There are several drawbacks to taking a top-down approach, the biggest one being the large, upfront investment: features that are working today will take time to rebuild using the new approach. Reimplementing legacy features is a difficult task, as often the system has very specific quirks that have been patched in across iterations of the software. Some of these quirks may even be the preferred workflow for users. Rebuilding an entire application will always result in unexpected challenges and results. Large companies like Uber developed their RIBS architecture during a well-documented rewrite. Pinterest explored a completely new architecture by starting from scratch. With so many different risks, it is often difficult to estimate the amount of time a top-down approach will take. A top-down approach increases the risk of instability in an existing project as there are lots of moving parts: everything is being rewritten, engineers may need access to the same segments of code, or the chain of dependencies may be non-trivial.
Bottom-up
A bottom-up approach, sometimes referred to as the Strangler Fig Pattern, named after the Strangler Fig tree, allows new technologies to be adopted at a measured pace, rather than disrupting the entire application. New features can be built by leveraging existing interfaces, or introducing new ones, without impacting upstream or downstream features. Legacy features can be rebuilt using the new technology incrementally, rather than all at once. New code paths can be validated using AB testing before retiring the legacy implementation.
Introducing the new approach at a measured pace allows engineers more time to get comfortable with the new technology, as features can be implemented using the legacy or new approach, until such a time as the new approach is proven.
As with any alternative approach, there are associated costs. The first few features tend to be agnostic to legacy code, but there will be a point where the two approaches will need to exchange information. Depending on the architecture and choices made, bridging or translation code may need to be built. This requires extra time from the engineers who are familiar with both patterns. Building these bridges tends to allow legacy code to linger in the system much longer than a top-down rewrite. The system will develop multiple patterns to solve similar problems, which makes it much more difficult for new engineers to onboard and take “the right approach” when implementing a new feature. In extreme cases, if the new approach isn’t fully adopted, or is even abandoned, the bottom-up approach will have added a significant amount of tech debt, effectively negating the gains supposedly being provided by the new technology.
A quick recap of DoorDash’s use of the VIPER architecture
DoorDash uses the VIPER architecture to great effect, allowing isolation between features as they are developed. The isolation provided an incredible opportunity to build features much faster given the team’s level of experience with SwiftUI. Further details of the VIPER architecture are available in many articles. We recommend the one published by the team from Objc.io: Architecting iOS Apps with VIPER.
DoorDash’s Dasher application is built using a collection of modules. Typically, each Module represents a specific feature, such as receiving an incoming order or reviewing your personal ratings. Modules are self-contained and always utilize a View, Interactor, and Presenter to ensure a one-way flow of information.
Views make requests to Interactors, who in turn retrieve Entities from remote services. Once a request has been completed, the Interactor will then hand the data to the Presenter, which translates the data for the View to display. Routers are used in more complex use cases to manage how and when a new View should be presented.
Anyone familiar with SwiftUI will likely spot an immediate barrier to adoption. SwiftUI prefers bi-directional data flow provided by property wrappers such as @State and @Binding. The team was faced with a choice:
- Continue implementing the View layer with UIKit, build a reactive architecture inside our application, and move wholesale to SwiftUI and Combine
- Strike a balance, and develop a solution that could allow individual modules to decide whether or not they were using SwiftUI or UIKit.
How DoorDash integrated SwiftUI into a VIPER-based app with a bottom-up approach
Our team chose to introduce a way to use SwiftUI within the confines of our VIP architecture. This approach would only be applied to the new features we were building as a way to prove SwiftUI could be reliably integrated within the Dasher application alongside our existing UIKit features. Our approach would avoid the significant time investment of rewriting existing features and instead allow the View layer to become an implementation detail that varied between modules.
Our approach to integrate SwiftUI into a VIP architecture required a few additional elements:
State:- A module-level reference type
- Serves as a Single Source of Truth for the module data
- A receiver for data passed via the Presenter
- A container for various combine publishers, which produce down-stream data and state (to be consumed by one or more ViewModel instances)
ViewModel:- A view-level reference type
- An Observable that calculates ViewState deltas
ViewState:- A view-level value type
- Encapsulates data received via state changes, as driven by the Presenter

Figure 1 demonstrates the unidirectional data flow of Reactive VIP. The typical UIViewController subclass is replaced by a UIHostingController. The ViewModel adopts the communication path to the Interactor formerly owned by the View. The hosting controller would be responsible for constructing and displaying the root-level SwiftUI View for the Module. The hosting controller would also own the module-level State, acting as a source of truth for all data in the Module. Construction of the top-level SwiftUI View inside the hosting controller’s init function would allow the root ViewModel to reference the values published from the module’s State object. Data received from the Presenter would be received in the hosting controller, as is typically the case in VIP, but the data would be passed as-is to the appropriate part of the module’s State. ViewModels would then expose a ViewState to their respective SwiftUI views which act as a snapshot in time.
It’s no secret that navigation in SwiftUI is a topic of great debate. Given that we were building features in a contained way with SwiftUI inside VIP, we completely delegate navigation to VIP via Routers. This ensured app navigation was always handled through a consistent interface.
Getting started with Reactive VIP
Consider a feature where we want to keep track of the number of times a user has tapped a button. To keep track of the tap count, we might need to call the backend to record the count, the backend will then return the updated data and then we should display the latest information to the user. Let’s break the feature down based on the architecture above.
Traditional VIP elements
Module
- Navigation and external communication passes through this element
- Receives and manages app life cycle events (if needed)
- Constructs the VIP elements, retaining ownership of the View
struct Entity {
let name: String
let count: Int
}
class Module {
let view: ViewProtocol
init() {
let presenter = MyPresenter()
let interactor = MyInteractor(presenter: presenter)
self.view = MyHostingController(interactor: interactor)
presenter.view = view
}
}
View (Hosting Controller)
UIHostingControlleracts as a bridge between UIKit and SwiftUI- UIKit’s life cycle ends here and SwiftUI begins from here
- The
rootViewis not recreated every time data changes
protocol ViewProtocol: UIViewController {
func showUpdatedContent(
updatedName: String,
updatedCount: Int
)
}
class MyHostingController: UIHostingController<MyView> {
private let state = MyState()
private let interactor: Interactor
init(interactor: Interactor) {
self.interactor = interactor
// In some cases, the hosting controller can create an
// intermediate type to publish property changes to the
// ViewModel all at once.
// e.g.
//
// let viewStoreSubject = PassthroughSubject<ViewStore, Never>
//
// struct ViewStore {
// let updatedName: String
// let updatedCount :Int
// }
//
let namePublisher = state.$name.eraseToAnyPublisher()
let countPublisher = state.$count.eraseToAnyPublisher()
let myView = MyView(viewModel: .init(
namePublisher: namePublisher,
countPublisher: countPublisher,
interactor: interactor
))
super.init(rootView: myView)
}
@MainActor required dynamic init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
}
extension MyHostingController: ViewProtocol {
func showUpdatedContent(updatedName: String, updatedCount: Int) {
DispatchQueue.main.async { [weak self] in
self?.state.name = updatedName
self?.state.count = updatedCount
}
}
}
Interactor
- Handles actions received from the
Viewlayer - Communicates with various services including analytics, logging, or side-effects produced by user actions
- Dependencies can be injected here to access services provided by other areas of the system
protocol Interactor {
func didTap()
}
class MyInteractor: Interactor {
private let presenter: Presenter
private var entity = Entity(
name: "Mr. SwiftUI",
count: 0
)
init(presenter: Presenter) {
self.presenter = presenter
}
func didTap() {
// Sample business logic
entity = Entity(
name: entity.name,
count: entity.count + 1
)
DispatchQueue.global().async { [weak presenter, entity] in
presenter?.update(from: entity)
}
}
}Presenter
- Abstracts the
Viewlayer from theInteractor - Transforms data received from services for the
Viewlayer - Very lightweight, least amount of responsibilities of all elements
protocol Presenter: AnyObject {
func update(from entity: Entity)
}
class MyPresenter: Presenter {
weak var view: ViewProtocol?
func update(from entity: Entity) {
view?.showUpdatedContent(
updatedName: entity.name,
updatedCount: entity.count
)
}
}
Reactive Components
State
- Acts as a single source of truth for the module
- Passes data to SwiftUI via published changes
- Lives in the same file as the hosting controller as a private element
private class MyState: ObservableObject {
@Published var name = ""
@Published var count = 0
}
View (SwiftUI)
ViewStateestablishes a one-to-one relationship between the SwiftUIViewand the source of truth- This approach ensures that there is a single direction of communication
- Business logic is migrated out of the
Viewlayer, making it much easier to mock and test
struct MyView: View {
struct ViewState {
var name: String
var totalTaps: Int
}
@ObservedObject var viewModel: MyViewModel
var body: some View {
VStack {
Text("Hello \(viewModel.viewState.name)")
Text("You pressed the button \(viewModel.viewState.totalTaps) time(s)")
Button {
viewModel.buttonTapped()
} label: {
Text("Tap Me")
}
}
}
}
struct MyView_Previews: PreviewProvider {
static var previews: some View {
MyView(viewModel: .init(
namePublisher: Just("Name").eraseToAnyPublisher(),
countPublisher: Just(0).eraseToAnyPublisher(),
interactor: MyInteractor(presenter: MyPresenter())
))
}
}
ViewModel
- The
ViewModelacts as a data bridge - Accepts data via the State’s published properties
- Signals user actions to the interactor
- Abstracts these dependencies makes it easy to unit test
ViewModels
class MyViewModel: ObservableObject {
@Published var viewState = MyView.ViewState(
name: "",
totalTaps: 0
)
private let interactor: Interactor
private var namePublisherCancellable: AnyCancellable?
private var countPublisherCancellable: AnyCancellable?
init(
namePublisher: AnyPublisher<String, Never>,
countPublisher: AnyPublisher<Int, Never>,
interactor: Interactor
) {
self.interactor = interactor
self.namePublisherCancellable = namePublisher
.sink { [weak self] newName in
self?.viewState.name = newName
}
self.countPublisherCancellable = countPublisher
.sink { [weak self] newCount in
self?.viewState.totalTaps = newCount
}
}
func buttonTapped() {
interactor.didTap()
}
}
Deliver features faster, with better testability using SwiftUI
Adopting SwiftUI with a bottom-up approach was a huge win for our project in a number of different ways. The team was able to deliver view-based tasks 50% faster than was previously possible, much of this is attributed to reduced iteration time thanks to SwiftUI previews and fewer lines of code needed compared to a UIKit view.
Adding these additional elements to our architecture accounted for a small amount of overhead, but this was balanced by a reduction in the Interactor and Presenter layers. Future iterations on our architecture may include removal of these layers, but our initial goals were to modify the View layer and maintain VIP architecture patterns to ensure compatibility with other UIKit-based modules.
Another big win was increased testability thanks to the 1:1 relationship of ViewModels to Views. ViewModels were simple enough that they could be mocked, which allowed us to implement snapshot testing with a small amount of additional work, which we had time for as a direct result of reduced view implementation times.
This win was significant since SwiftUI adoption has been limited. iOS 13 introduced SwiftUI, but on a limited scale and with a significant amount of issues. Many engineers are hesitant to adopt SwiftUI as they feel it is not “enterprise ready”. This experience suggests engineers should review the statistics of their install base, as the same devices can run iOS 13, 14, and 15. Take advantage of the improvements later versions of SwiftUI offer and bump the minimum version today–we did!
Our next goal is to broaden the adoption of our solution and to help other engineers bring SwiftUI to their features.
How you can adopt SwiftUI in your enterprise project today
As many engineers know, implementing features with a high degree of velocity is a key factor in today’s product-driven economy. It can be very difficult to sell product stakeholders a plan to rewrite an entire application. The effort involved is always extensive, and it can be difficult to achieve feature parity in a short amount of time, let alone add something new. It can prove to be more difficult if there are constraints around testers, or if the system lacks a comprehensive set of feature-level tests.
Adopting SwiftUI in an enterprise-grade application can also be a tough sell, many architectures are built around UIKit’s procedural model. These factors make it crucially important to identify a small enough slice of your architecture to support SwiftUI. Working within these confines, adopt SwiftUI with a bottom-up approach to mitigate much of the downside of a rewrite and take advantage of the speed and testability offered by SwiftUI in your development cycles. New features can be written alongside existing ones without introducing additional hurdles for others working on your product. Existing features can be left as-is, or a plan can be established to rewrite them at an acceptable pace, but they won’t hinder the system as a whole.