

Today, many of the fastest growing, most successful companies are data-driven.
Category Archives: AI & ML
Leveraging Causal Modeling to Get More Value from Flat Experiment Results
A/B tests and multivariate experiments provide a principled way of analyzing whether a product change improves business metrics.
Retraining Machine Learning Models in the Wake of COVID-19

The advent of the COVID-19 pandemic created significant changes in how people took their meals, causing greater demand for food deliveries.
Supporting Rapid Product Iteration with an Experimentation Analysis Platform

DoorDash’s new experimentation platform, built on a combination of SQL, Kubernetes, and Python, allows for quick iteration of data-driven feature improvements.
Using a Human-in-the-Loop to Overcome the Cold Start Problem in Menu Item Tagging

Companies with large digital catalogs often have lots of free text data about their items, but very few actual labels, making it difficult to analyze the data and develop new features.
Building a system that can support machine learning (ML)-powered search and discovery features while simultaneously being interpretable enough for business users to develop curated experiences is difficult.
Optimizing DoorDash’s Marketing Spend with Machine Learning
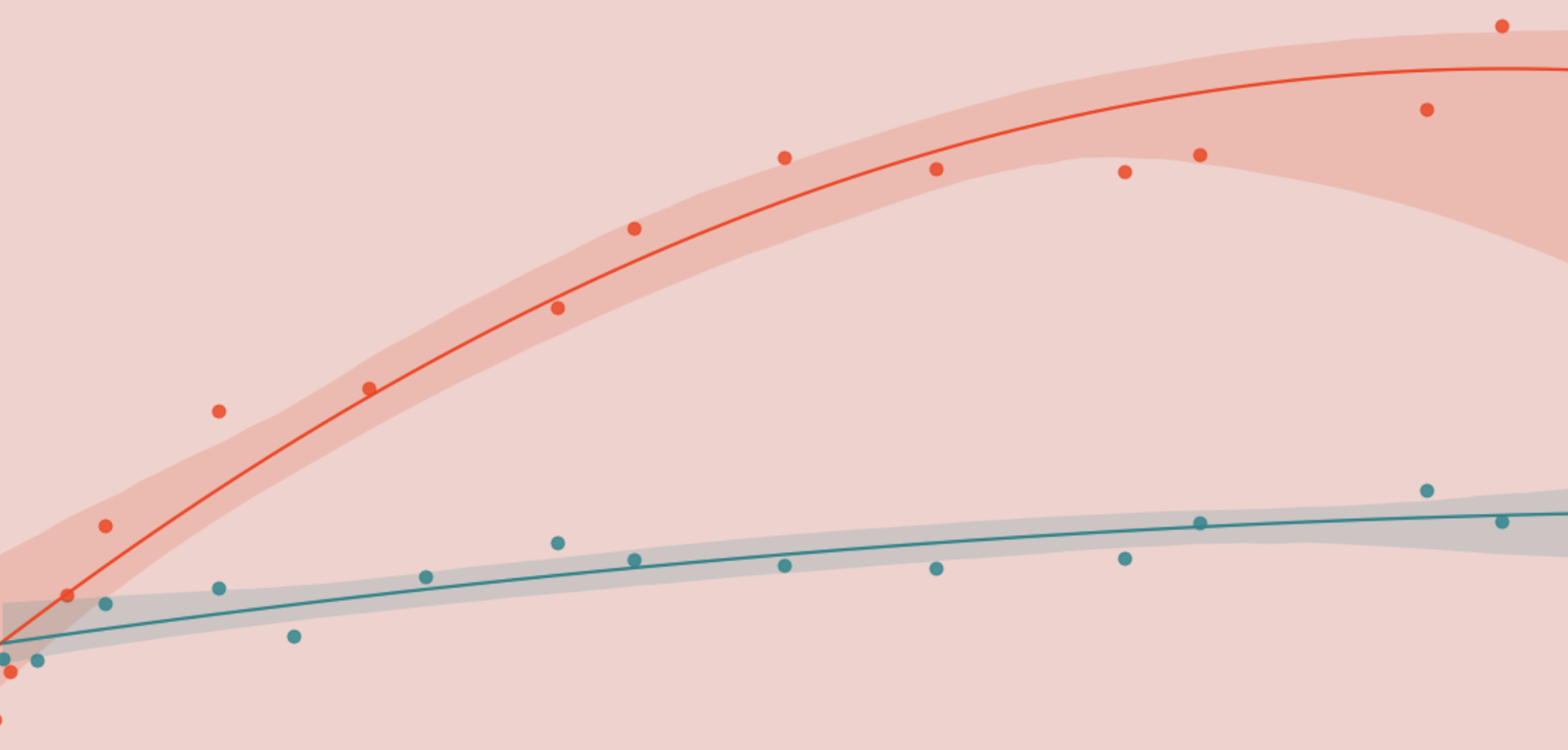
Over a hundred years ago, John Wanamaker famously said “Half the money I spend on advertising is wasted; the trouble is, I don’t know which half”.
Enabling Efficient Machine Learning Model Serving by Minimizing Network Overheads with gRPC

The challenge of building machine learning (ML)-powered applications is running inferences on large volumes of data and returning a prediction over the network within milliseconds, which can’t be done without minimizing network overheads.
Meet Sibyl – DoorDash’s New Prediction Service – Learn about its Ideation, Implementation and Rollout

As companies utilize data to optimize and personalize customer experiences, it becomes increasingly important to implement services that can run machine learning models on massive amounts of data to quickly generate large-scale predictions.
Improving Experimental Power through Control Using Predictions as Covariate (CUPAC)
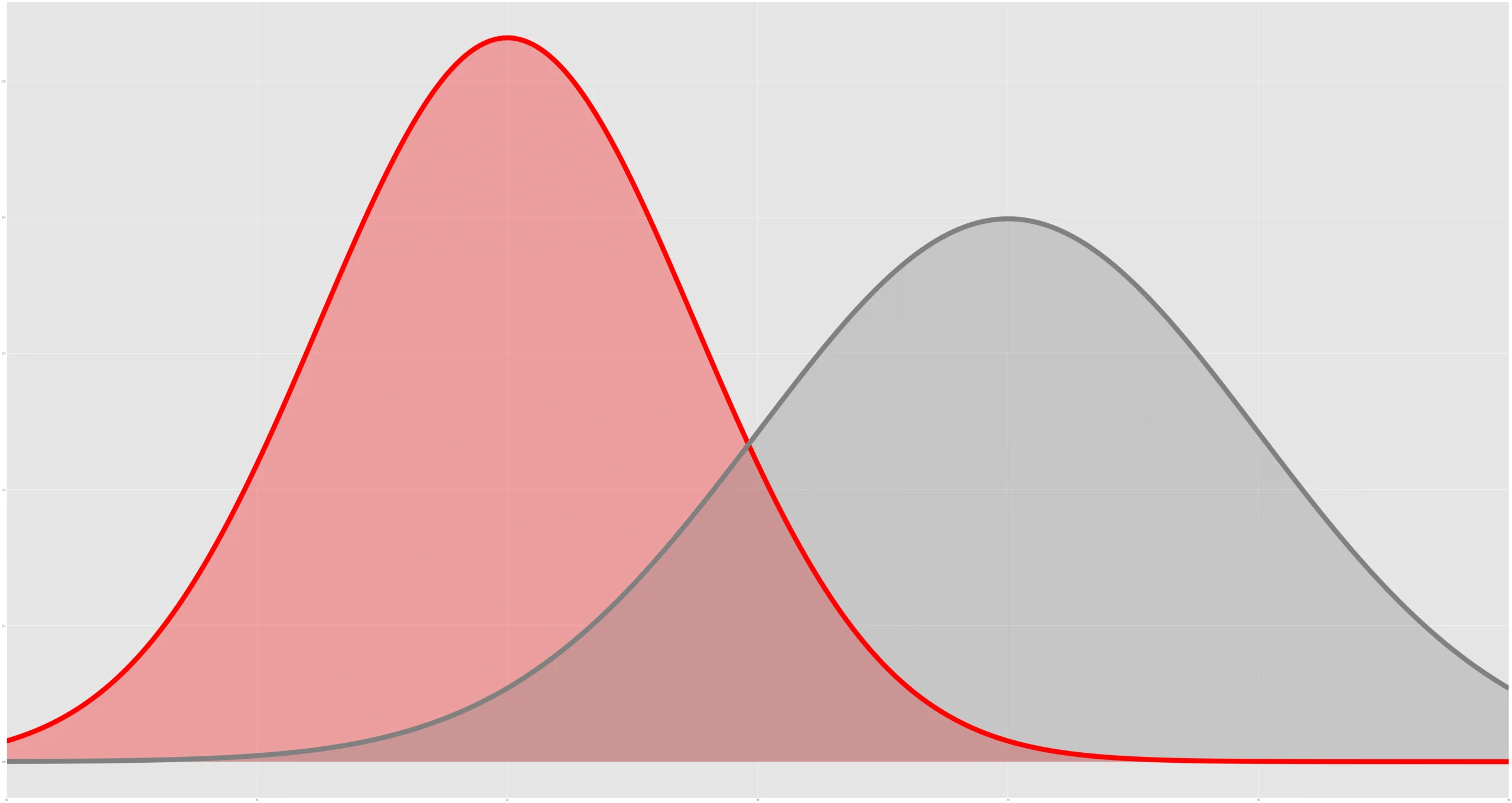
In this post, we introduce a method we call CUPAC (Control Using Predictions As Covariates) that we successfully deployed to reduce extraneous noise in online controlled experiments, thereby accelerating our experimental velocity.
Rapid experimentation is essential to helping DoorDash push key performance metrics forward.
DoorDash’s ML Platform – The Beginning

DoorDash uses Machine Learning (ML) at various places like inputs to Dasher Assignment Optimization, balancing Supply & Demand, Fraud prediction, Search Ranking, Menu classification, Recommendations etc.