

The advent of the COVID-19 pandemic created significant changes in how people took their meals, causing greater demand for food deliveries. These changes impacted the accuracy of DoorDash’s machine learning (ML) demand prediction models. ML models rely on patterns in historical data to make predictions, but life-as-usual data can’t project to once-in-a-lifetime events like a pandemic. With restaurants closed to indoor dining across much of the country due to COVID-19, more people were ordering in, and more restaurants signed on to DoorDash for delivery.
DoorDash uses ML models to predict food delivery demand, allowing us to determine how many Dashers (drivers) we need in a given area at any point in time. Historically, demand patterns are cyclical on hourly, weekly, and seasonal time scales with predictable growth. However, the COVID-19 pandemic brought demand patterns higher and more volatile than ever before, making it necessary to retrain our prediction models to maintain performance.
Maintaining accurate demand models is critical for estimating how many Dashers are needed to fulfill orders. Underestimating demand means customers won’t receive their food on time, as fewer Dashers will be on hand to make deliveries. Alternatively, overestimating demand and overallocating Dashers means they can’t maximize their earnings, because there won't be enough orders to go around.
We needed to update our prediction models so they remained accurate and robust. Delivering reliable predictions under conditions of volatility required us to explore beyond tried and true training techniques.
Maintaining our marketplace
The supply and demand team at DoorDash focuses on balancing demand and number of Dashers at any given time and in any region. Being able to predict future marketplace conditions is very important to us, as predictions allow us to offer promotional pay and notify Dasher’s of a busy marketplace in advance to preempt Dasher-demand imbalances. By doing so, we allow Dashers to deliver and thus earn more, while also enabling faster delivery times for consumers.
Percentile demand model
As a component of our expected demand prediction, we maintain a percentile demand model (PDM) designed to predict within a range of percentiles designed to optimize deliveries. In contrast to an expected demand model, percentile models give us a wider range of insights, allow us to draw confidence intervals, and enable us to take more precise actions.
The model is a gradient boosted decision tree model (GBM) using dozens of estimators and features sourced from a table designed to aggregate features useful for ML tasks (eg. demand X days ago, the number of new customers gained, and whether a day is a holiday). The model uses a quantile loss function,

where ŷ is our prediction, y is the true label, and ɑ is represents a percentile. When we overpredict (ŷ > y), the max function will return its first term, which is the difference between our prediction and the true value multiplied by ɑ. When we underpredict (y > ŷ), the max function returns its second term, which is the same difference multiplied by (1 - ɑ). Thus, this model can be parameterized to penalize overpredictions and underpredictions differently.
The model makes thousands of demand predictions a day, one for each region and 30 minute time frame (region-interval). We weigh the importance of a region-interval’s predictions by the number of deliveries that region-interval receives, calculating each-day’s overall weighted demand prediction percentile (WDPP) as follows:
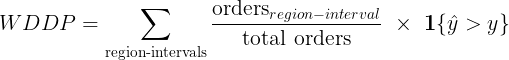
Where orders region-interval is the number of orders in a region-interval, the summation is over all region-intervals, and the identity function 1{ŷ > y} is 1 on overpredict and 0 otherwise.
How COVID-19 disrupted our predictions
The main impetus for retraining our model was changing demand patterns due to COVID-19. Our models have learned that consumers tend to dine out during the warmer March through May months, but the pandemic bucked those trends.

The old demand prediction model (DPM) began severely underpredicting demand once COVID-19 restrictions were put into place and an increasing number of consumers ordered food online. Although the model showed some adaptability to new conditions and its performance recovered, we decided to use the new COVID-19 demand data to see if updating the model would yield performance benefits.
Retraining our percentile demand model
In retraining our demand percentile model, we evaluated it on its ability to predict within its percentile range more consistently than the old model. We also used other metrics like quantile loss as heuristic guides and validated the model’s impact on business metrics before deployment.
Ultimately, the model retraining and prediction scripts will be deployed to our ETL job hosted on Apache Airflow. To enable fast iteration, however, we developed the model on Databricks’ hosted notebooks using a standard ML stack based on Pandas and LightGBM.
We elected to not experiment with the type of model we used, as GBMs are commonly acknowledged to yield good performance on mid-sized datasets like ours. Instead, we focused our investigation on three main categories: dataset manipulation, hyperparameter tuning, and feature engineering.
Hyperparameter tuning
Our old DPM was parameterized to target the upper threshold of the ideal percentile range and then tuned to underpredict so that its predictions fell in range. Although this strategy yielded generally accurate predictions before COVID-19, we hypothesized that parameterizing our model to target the midpoint of the ideal percentile range and then tuning to minimize variance would improve performance. Our experiments confirmed this hypothesis.
With the new setting, we ran a series of random hyperparameter searches. We did not find a configuration we could use out of the box, but we did discover that the number of estimators in our DPM was by far the most influential factor in its performance, allowing us to focus our hyperparameter tuning efforts.
We found that models with underfitting hyperparameters (eg. few estimators, number of leaves, and max depth) tended to have a mean WDPP close to , but also a higher loss and WDPP standard deviation. This suggests that underfit models are less biased towards the training set, but also return looser predictions. Inversely, overfit models had mean WDPP further from , but also lower quartile loss and WDPP standard deviation because they make tighter predictions that were also more biased towards the training set. This is consistent with the bias-variance tradeoff problem.
With these insights, we settled on using 40 estimators and ɑ at the midpoint of the ideal percentile range; the other hyperparameters had little impact on model performance and we left them at values close to their defaults.
Dataset manipulation
In contrast to our smooth-sailing hyperparameter tuning process, our experiments in dataset manipulation ultimately disproved some of our most promising hypotheses.
First, because heightened demand following COVID-19 dramatically impacted our old PDM performance, we hypothesized that we can improve performance by selectively retraining our new PDM on subsets of the historic data. As a result, we categorized our available data into three periods: 1) the pre-pandemic phase 2) the early-pandemic phase, and 3) the late-pandemic phase.
We downsampled data from the pre-pandemic phase on the intuition that pre-COVID-19 data is less representative of current demand patterns. Separately, we downsampled data from the early-pandemic phase based on the intuition that the volatile demand following the earliest COVID-19 restrictions is not representative of the more predictable patterns we see now. However, after retraining our model over both altered datasets we found the modifications to be negligible or detrimental to model performance, highlighting the unintuitive nature of ML model performance.
Next, we removed training data from holidays on the intuition that abnormal demand observed on holidays is not representative of usual demand. Removing data from holidays had a negligible effect on performance. We believe this result is because our model uses features that encode demand from up to several previous weeks (eg. demand 14 days ago), meaning that removing one day’s worth of data does not prevent that data from influencing future predictions.
Finally, we expanded our training set to include all data from the past year, compared to the original PDM which was only trained on eight weeks of historical data. This expanded dataset significantly improved model performance. Our results show that the benefits to generalizability gained by training over more data ultimately outweighed the downsides of using outdated data not representative of current patterns.
Feature engineering
Our experiments in feature engineering, like those in dataset manipulation, initially ran counter to our expectations. But ultimately, some of our most insightful changes to our model would be in how we represented our features.
As we began examining our model’s features, we hypothesized that our model’s degraded performance is partially caused by features that appropriately influence a model trained on pre-pandemic demand, but degrade the predictions of a model trained on demand since the pandemic. To test this hypothesis, we trained two models, one on pre-pandemic data and one on pandemic data (roughly comprising the early- and late-pandemic data of the previous section). We then leveraged an ML visualization technique called SHAP plots to see how our features influenced each model.

By comparing the effects of individual features, we found that features encoding past demand (eg. demand three days ago) tend to inflate predicted demand in models trained on pandemic data in comparison to models trained before. We posit that this inflation occurs because demand growth following COVID-19 restrictions taught our model that new demand tends to significantly exceed past demand. This expectation often causes our model to overpredict, and we hypothesized that removing some historical demand features would improve model performance. However, our experiments showed that removing these features is detrimental to model performance, reinforcing the difficulty of speculating about ML model performance.
Using SHAP plots, we also identified features that were not correlated with predicted demand. In Figure 2, above, the smooth red to blue gradient of the first row shows that its corresponding feature is correlated with the prediction value, while the jumbled dots of the bottom-half rows show that their features are not. In our model, we removed several features whose SHAP plots were similar to that of the bottom half rows in Figure 2, yielding marginal performance improvements.
Finally, we reformulated existing features into new representations that directly encode information relevant to our model. For example, we changed our prediction date feature from a timestamp to a categorical feature representing the day of the week and reformulated a time-of-day feature from a timestamp to a numeric encoding of temporal distance from meals.
These features resulted in significant improvements in model performance, validated by the fact that their SHAP plots showed a strong correlation with demand. This finding indicated that GBMs are not powerful enough to implicitly convert from date to day-of-week or time to duration-from-dinner, and that manual specification of such features is beneficial for improving model performance.
Results
After tuning our new DPM as described, we compared its performance within a three week test interval to the old DPM model. The old DPM achieved prediction variance of 7.9%, with its WDPP value falling within its percentile range 67% of the time. The new DPM yielded a prediction variance of just 2.8%, remaining within the percentile range 95% of the time. This was an improvement because it meant that our newer model was much more accurate while just as precise.
| New DPM | Old DPM | |
| Prediction variance | 2.8% | 7.9% |
| Percent in SLA | 95% | 67% |
Following these improvements, we partially deployed our new DPM by routing half of our prediction traffic to the new DPM and half to the old. After verifying that the new DPM affects business metrics favorably, we will deploy it across all our prediction traffic.
Conclusion
The volatile demand that DoorDash experienced during the early days of the COVID-19 pandemic put our demand prediction models to the test. Despite these challenges, we were able to not only recover, but improve, our model’s performance.
Through our model tuning process, we obtained a number of key learnings for optimizing ML performance in our use cases similar to ours:
- First, some hyperparameters can have a disproportionate impact on model performance, while others may have little effect at all. It’s useful to identify impactful hyperparameters and focus on them during model tuning.
- Second, GBMs may not be powerful enough to implicitly create intermediate features like day-of-week from a date. In such cases, human expertise is necessary to encode features in representations directly useful to the model.
- Third, the benefits to generalizability gained by training over more data can outweigh the downsides of using outdated data not representative of current patterns.
- Fourth, model observability is very important. SHAP plots, for example, can provide many insights that loss or accuracy alone could never yield.
- Finally, and most hard-learned of all, the cleverness of an idea in ML can have little bearing on how it performs in practice. Intuition serves as a guide, but cannot replace experimentation.
We hope these insights will allow us to iterate faster in modeling demand, which in turn will enable us to better serve our customers, merchants, and Dashers.
Austin Cai joined DoorDash for our 2020 Summer engineering internship program. DoorDash engineering interns integrate with teams to learn collaboration and deployment skills not generally taught in the classroom.