

The independent contractors who do deliveries through DoorDash — “Dashers” — pick up orders from merchants and deliver them to customers. That process, however, is far more complex than it appears to be on the surface. Dashers, particularly those new to the process, sometimes need support to resolve issues they encounter in the delivery process. This post describes how we have worked to improve the existing Dasher support system using large language models, or LLMs, and a retrieval augmented generation system, or RAG. We also describe how we manage the improved system with LLM Judge, LLM Guardrail, and quality evaluation.
When Dashers encounter difficulties during delivery, they can reach out to DoorDash support. We provide automated solutions and can connect Dashers to human support agents as needed. The automated support system typically resolves issues faster than human agents can because Dashers are connected instantly to a system that provides answers at digital speed. Our existing automated support system, however, provides flow-based resolutions, relying heavily on pre-built resolution paths. This means that only a small subset of Dasher issues can be resolved quickly. Although we offer Dashers a good collection of articles in our knowledge base, three issues limit their usefulness:
- It can be difficult to find the relevant article;
- It takes time to find useful information within any particular article;
- The articles are all in English, but many Dashers prefer a different language.
These problems form a perfect use case for a RAG system that retrieves information from knowledge base articles to generate a response that resolves Dasher issues efficiently.
RAG adoption challenges
With the recent developments in chatbot technology, large language models, or LLMs, such as GPT-4 and Claude-3 now can produce responses that mimic human quality and fluency. But as with any sophisticated system, they do occasionally produce errors. If not addressed, these errors can lead to significant issues.
We've identified several challenges while working with LLMs:
- Groundedness and relevance of responses in RAG system
Our LLM RAG chatbot has in some cases generated responses that diverged from the intended context. Although these responses sound natural and legitimate, users may not realize that they are inaccurate. These discrepancies often stem from outdated or incorrect DoorDash-related information included during the LLM's training phase. Because LLMs typically draw from publicly available text, including discussions on platforms such as Quora, Reddit, and Twitter, there is a heightened risk of propagating erroneous information. As a result, users may not get what they need from our chatbot. - Context summarization accuracy
We must first understand the Dasher’s issue before we can retrieve the most relevant information. Additionally, if there has been a multi-turn conversation between a Dasher and our chatbot system, we must summarize the issue from that dialogue. The issue changes as a conversation progresses; the summary’s presentation affects the result produced by the retrieval system. The summarization system has to be highly accurate for the remaining parts of the RAG system to provide the correct resolution.
- Language consistency in responses
Language consistency is paramount, especially when users interact with the chatbot in languages other than English. Because LLMs primarily train on English data, they may occasionally overlook instructions to respond in a different language, particularly when the prompt itself is in English. This issue occurs infrequently and its occurrence diminishes as the LLM scales. - Consistent action and response
In addition to responding to the user, the LLM can also perform actions through calling APIs, but the function calls must be consistent with the response text. - Latency
Depending on the model used and the size of a prompt, latency can vary from a sub-second level to tens of seconds. Generally speaking, larger prompts lead to slower responses.
As detailed below, we developed three systems to resolve the RAG challenges: LLM Guardrail, LLM Judge, and a quality improvement pipeline as shown in Figure 1.
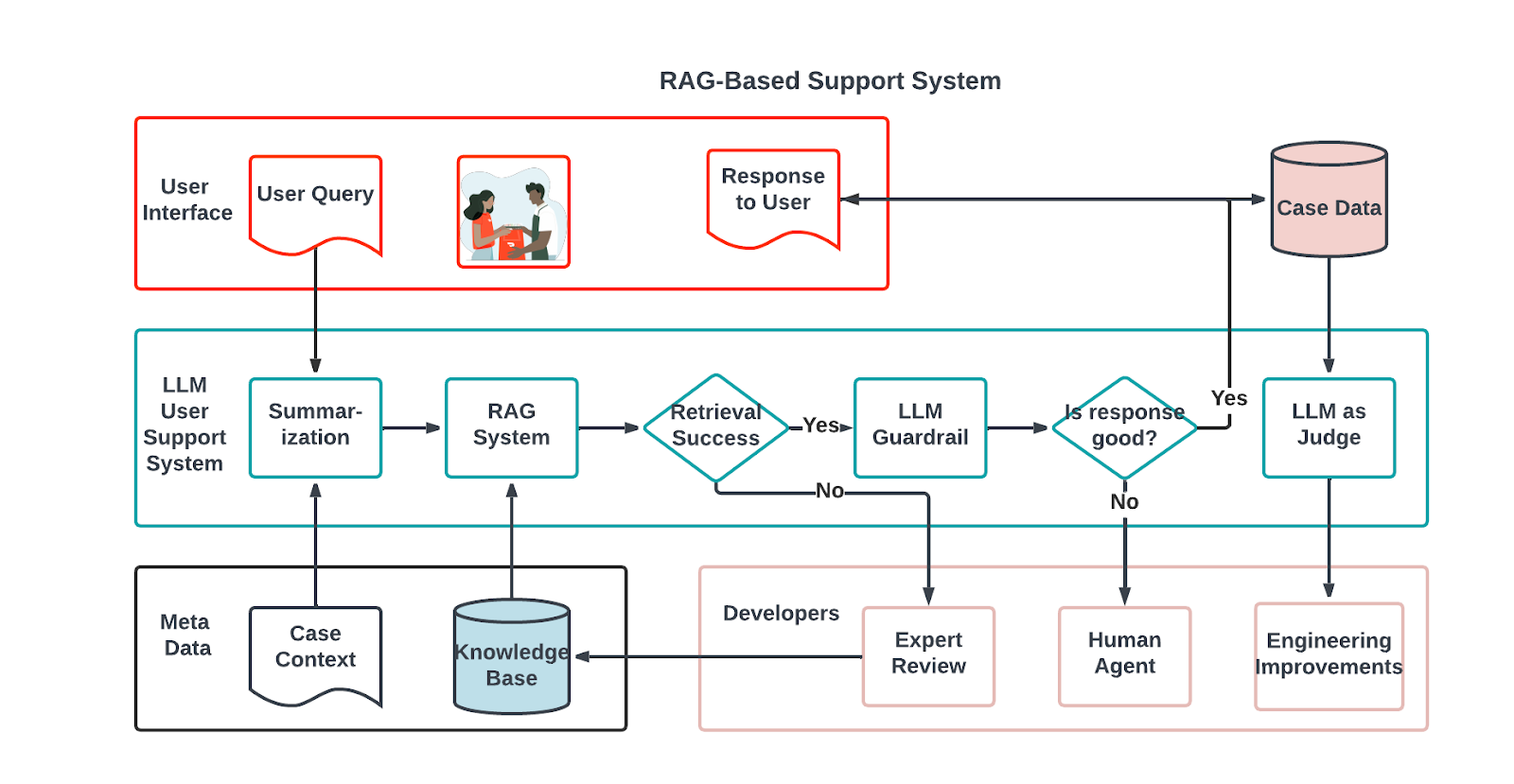
Implementing a RAG system
As noted earlier, the RAG system uses knowledge base, or KB, articles to enhance the Dasher support chatbot. The process, as outlined in Figure 2, begins when a Dasher presents an issue to the chatbot. Because the issue likely will be spread across several messages and follow-up questions, the system first condenses the entire conversation to pinpoint the core problem. Using this summary, it then searches historical data for the top N similar cases previously resolved with information from KB articles. Each identified issue corresponds to a specific article that is integrated into the prompt template. This enriched template allows the chatbot to generate a tailored response, leveraging the context of the conversation, the distilled issue summary, and any relevant KB articles to ensure that Dashers receive precise and informed support.

Response guardrail with LLM
The LLM Guardrail system is an online monitoring tool that evaluates each output from the LLM to ensure accuracy and compliance. It checks the grounding of RAG information to prevent hallucinations, maintains response coherence with previous conversations, and filters out responses that violate company policies.
A primary focus of the guardrail system is to detect hallucinations, where the LLM-generated responses are either unrelated or only partially related to KB articles. Initially, we tested a more sophisticated guardrail model but increased response times and heavy usage of model tokens made it prohibitively expensive. Instead, we adopted a two-tier approach: a cost-effective shallow check developed in-house followed by an LLM-based evaluator as shown in Figure 3.
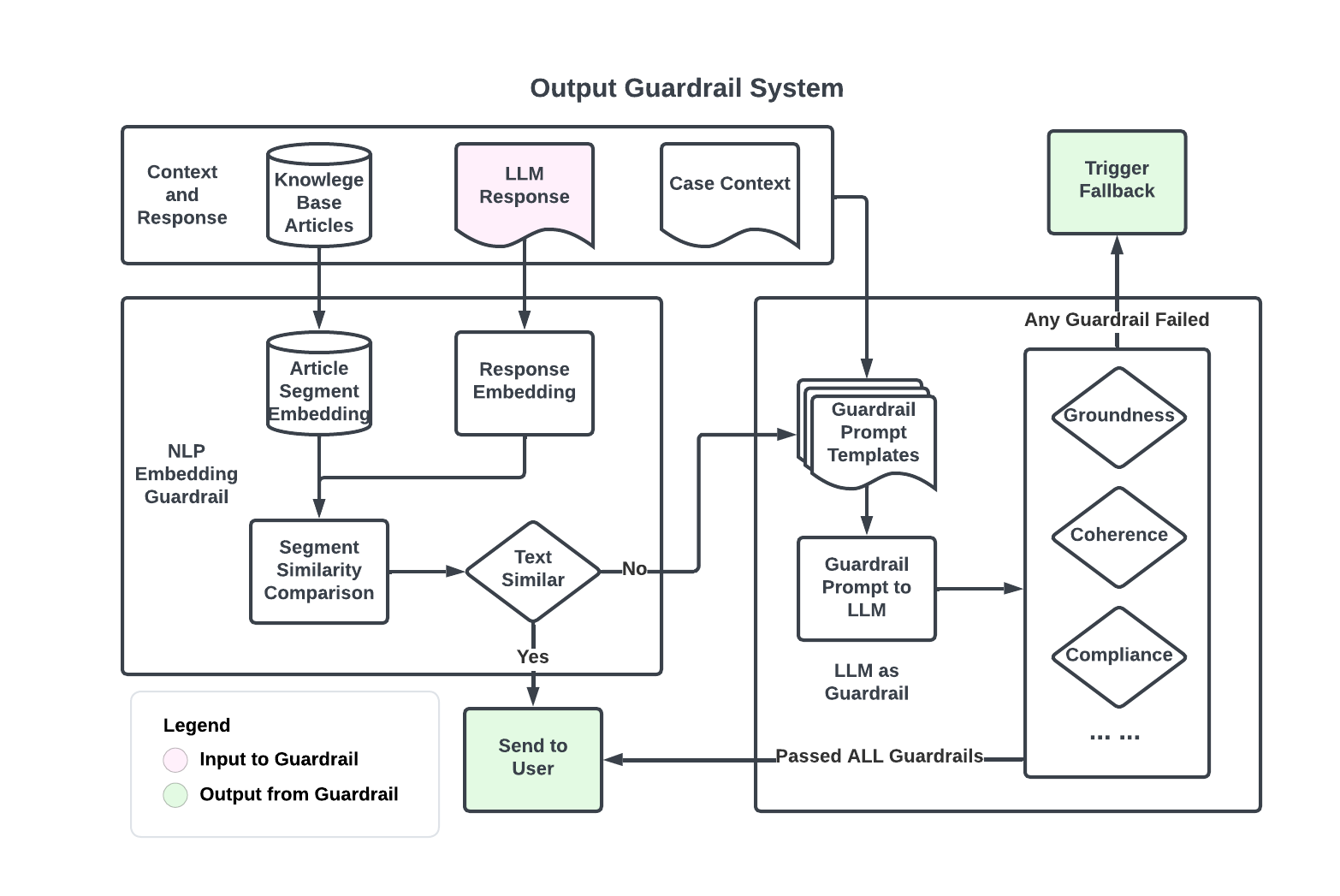
The first quality check layer is a semantic similarity comparison between the response and KB article segments. If this initial check fails, an LLM-powered second layer will further examine the response from multiple aspects including groundedness, coherence, and compliance. A response must pass all guardrail tests to be shown to the end user.
The shallow check employs a sliding window technique to measure similarities between LLM responses and relevant article segments. If a response closely matches an article, it's less likely to be a hallucination.
If the shallow check flags a response, we construct a prompt that includes the initial response, the relevant KB articles, and the conversation history. This is then passed to an evaluation model, which assesses whether the response is grounded in the provided information and, if necessary, offers a rationale for further debugging.
LLM Guardrail’s latency is a notable drawback caused by an end-to-end process that includes generating a response, applying the guardrail, and possibly retrying with a new guardrail check. Given the relatively small number of problematic responses, strategically defaulting to human agents can be an effective way to ensure a quality user experience while maintaining a high level of automation. This guardrail system has successfully reduced overall hallucinations by 90% and cut down potentially severe compliance issues by 99%.
Monitoring LLM Judge quality
We can evaluate the LLM’s quality from multiple perspectives, including Dasher feedback, human engagement rate, and delivery speed. None of these perspectives, however, provide actionable feedback that would allow us to improve our chatbot system. So we manually reviewed thousands of chat transcripts between the LLM and Dashers to develop an iteration pipeline for monitoring LLM quality. Our review allowed us to categorize LLM chatbot quality aspects into five areas:
- Retrieval correctness
- Response accuracy
- Grammar and language accuracy
- Coherence to context
- Relevance to the Dasher’s request
For each aspect, we built monitors either by prompting a more sophisticated LLM or creating rules-based regular expression metrics. The overall quality of each aspect is determined by prompting LLM Judge with open-ended questions, as shown in Figure 4. Answers to these questions are processed and summarized into common issues. The high-frequency issues are then built into prompts or rules for further monitoring.
Beyond the automated evaluation system, we also have a dedicated human team that reviews random subset transcript samples. A continuous calibration between this human review and the automated system ensures effective coverage.
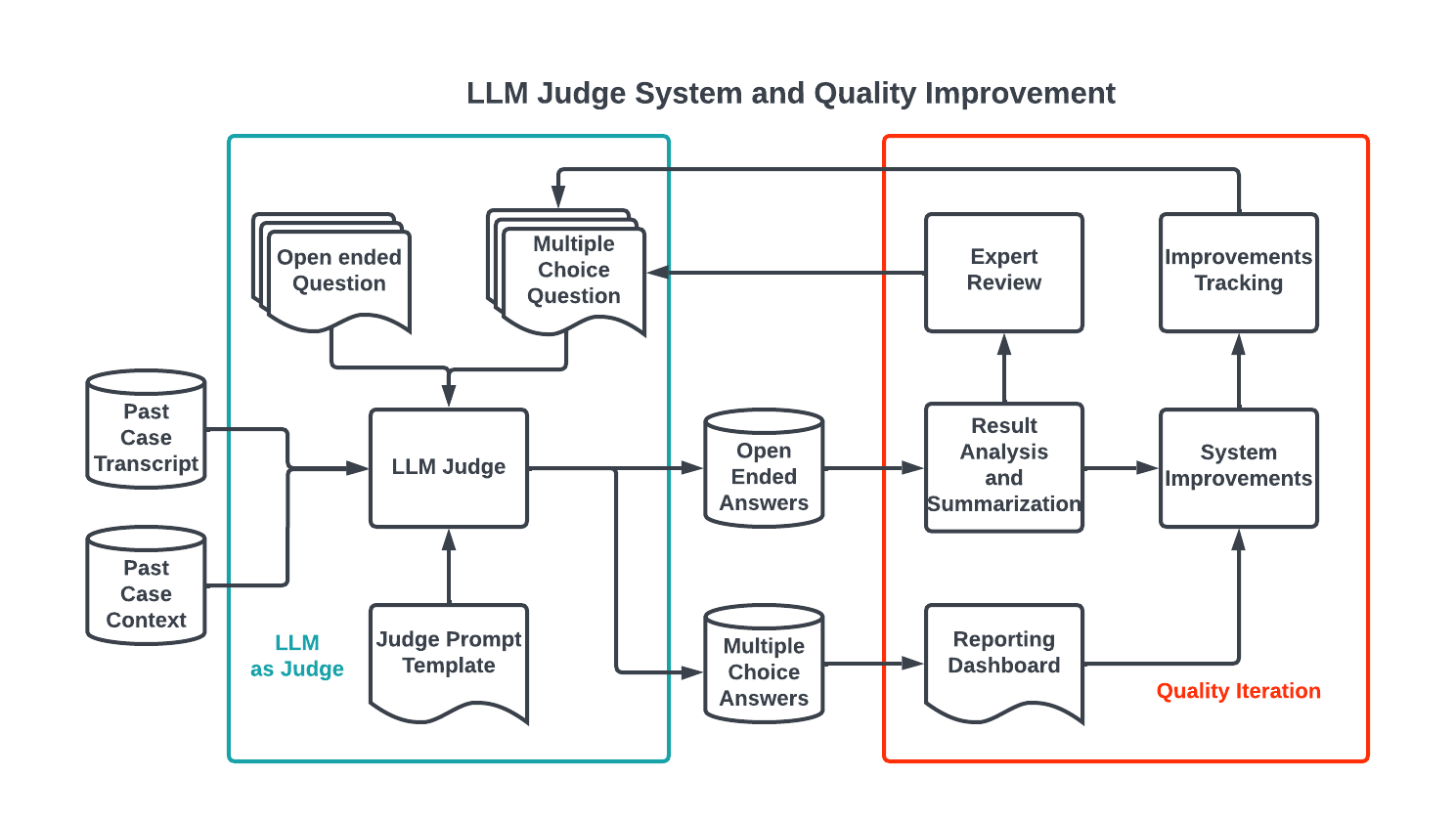
LLM quality improvement
Our system faces several quality challenges, including an insufficient knowledge base, inaccurate retrieval, model hallucination, and suboptimal prompts. Human support agents play a crucial role in addressing these issues, acting as subject matter experts, meticulously reviewing LLM responses, and guiding automated process enhancements. This collaborative effort between human expertise and machine learning is fundamental to refining the accuracy and reliability of our support system.
Knowledge base improvements
The knowledge base serves as the foundational truth for LLM responses, so it’s important to offer complete, accurately phrased articles. LLM Judge’s quality evaluation has allowed us to conduct thorough reviews and KB updates to eliminate misleading terminology. Additionally, we are developing a developer-friendly KB management portal to streamline the process for updating and expanding articles.
Retrieval improvements
Effective retrieval involves two key processes:
- Query contextualization: Simplifying queries to a single, concise prompt while providing context through a comprehensive conversation history.
- Article retrieval: Selecting an optimal embedding model from a few choices within our vector store to enhance retrieval accuracy.
Prompt improvements
We must refine prompts to guide the LLM accurately. This refinement process can either be straightforward or painful, depending on the base LLM model. We follow a few principles:
- Breaking down complex prompts into smaller, manageable parts and employing parallel processing where feasible.
- Avoiding negative language in prompts because models typically struggle with these. Instead, we clearly outline desired actions and provide illustrative examples.
- Implementing chain-of-thought prompting to encourage the model to process and display its reasoning, aiding in identification and correction of logic errors and hallucinations.
Regression prevention
To maintain prompt quality and model performance, we use an open-source evaluation tool akin to unit testing in software development. This tool allows us to refine prompts quickly and evaluate model responses. A suite of predefined tests is triggered by any prompt changes, blocking any failing prompts. Newly identified issues are systematically added to Promptfoo test suites, ensuring continuous improvement and preventing model performance regression.
Our success
We're revolutionizing Dasher support by using our new LLM-based chatbot to deploy our extensive knowledge base. Each day, this system autonomously assists thousands of Dashers, streamlining basic support requests while maximizing the value of human contributions. This collaborative system allows human support representatives to focus their energy on solving more complex problems for Dashers. Our quality monitoring and iterative improvement pipeline have transformed an initial prototype into a robust chatbot solution, creating a cornerstone for further advancements in our automation capabilities.
Looking into the future
Our LLM chatbot represents a shift from traditional flow-based systems, introducing a degree of uncertainty inherent to its underlying large language models. Ensuring high-quality responses is paramount for the success of any high-volume LLM application. Continuing to develop precise quality assessment methods will allow us to identify and narrow any performance gap between ideal experience and automated systems. While the chatbot system effectively handles routine inquiries, complex support scenarios will still require the expertise of live agents. As foundational models, ontology and RAG systems are enhanced over time, the efficacy of LLM-driven solutions also will improve. Continuous data collection and analysis are vital for guiding these enhancements to ensure that our systems remain agile and effective. As we move forward, we aim to expand the capabilities of automated solutions to address increasing complexity with the help of human customer support experts.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on



