

When trying to scale a distributed system a common obstacle is not that there aren’t enough resources available, it's that they are not being used efficiently.
At DoorDash we found a similar opportunity when working to scale our point-of-sale system (POS). We were experiencing outages because our POS system could not scale to meet peak demand. The problem was not a lack of resources, but that our resources were not being utilized efficiently.
DoorDash’ POS system collects new orders and sends them to merchants’ POS systems via their APIs. However, due to typical network and system latency, the time it took for the merchant’s endpoints to respond to the order creation requests was small but significant. Since the legacy system would wait for the merchant’s POS system to respond, our resource utilization efficiency was severely limited.
Our solution involved moving from a synchronous to an asynchronous input/output (I/O) model, which enabled our resources to be better utilized, scaled out our order capacity by 10x, and prevented additional outages.
The lifecycle of an order
DoorDash’s backend consists of several microservices which communicate via REST APIs or gRPC. Our POS microservice forwards orders to merchants.

After the user finishes the check out process, either on the DoorDash mobile app or the web site, the order is sent to the POS microservice. At this point the POS system forwards the order to the right merchant via a series of API calls.
Since sending the order to the merchant can take several seconds, the communication with POS is asynchronous and accomplished using Celery, a Python library that provides an RPC layer over different brokers, in our case RabbitMQ. The request for an order will then be picked up by one of the POS Kubernetes workers, processed, and forwarded to the merchant.
How we configured Celery
Celery is a distributed Python framework designed to manage asynchronous tasks. Each POS Kubernetes pod runs four Celery processes. Each process waits for a new task to be available, fetches it, and executes the Python callback to contact the merchant and create a new order. This process is synchronous and no new tasks can be executed by the Celery process until the current task has been completed.
The problems with the legacy approach
This legacy approach presents quite a few issues. First of all, resources are underutilized. When the order rate is high, most of the CPU time is spent waiting for merchant endpoints to respond. This time spent waiting for the merchant’s side to respond, along with the low number of Celery processes we configured, results in an average CPU usage below 5%. The overall effect of our legacy approach is that we end up requiring significantly more resources than needed, which limits how much the system can scale.
The second issue is that an increased latency in one merchant API can use up all the Celery tasks and cause requests to other (healthy) merchant APIs to pile up in RabbitMQ. When this pileup happened in the past it caused a significant order loss, which hurt the business and user confidence.
It was clear that increasing the number of Celery processes would have only slightly improved this situation since each process requires a significant amount of memory to run, limiting the maximum concurrency achievable.
The solutions we considered
To solve this POS problem we considered three options:
- Using a Python thread pool
- Taking advantage of Python 3’s AsyncIO feature
- Utilizing an asynchronous I/O library such as Gevent
Thread pool
A possible solution would be to move to a model with a single process and have a Python thread pool executor execute the tasks. Since the memory footprint of a thread is significantly lower than the one in the legacy process, this would have allowed us to significantly increase our level of concurrency, going from four Celery processes per pod to a single process with 50 to 100 threads.
The disadvantages of this thread pool approach are that, since Celery does not natively support multiple threads, we would have to write the logic to forward the tasks to the thread pool and we would have to manage concurrency, resulting in a significant increase in the code complexity.
AsyncIO
Python 3’s AsyncIO feature would have allowed us to have high concurrency without having to worry about synchronization since the context is switched only at well-defined points.
Unfortunately, when we considered using AsyncIO to solve this problem, the current Celery 4 was not supporting AsyncIO natively, making a potential implementation on our side significantly less straightforward.
Also, all the input/output libraries we use would need to support AsyncIO in order for this strategy to work properly with the rest of the code. This would have required us to replace some of the libraries we were using, such as HTTP, with other AsyncIO compatible libraries, resulting in potentially significant code changes.
Gevent
Eventually we decided to use Gevent, a Python library that wraps Python greenlets. Gevent works similarly to AsyncIO: when there is an operation that requires I/O, the execution context is switched to another part of the code that already had its previous I/O request fulfilled and therefore is ready to be executed. This method is similar to using Linux's select() function, but is transparently handled by Gevent instead.
Another advantage of Gevent is that Celery natively supports it, only requiring a change to the concurrency model. This support makes it easy to set up Gevent with existing tools.
Overall, using Gevent would solve the problem DoorDash faced by letting us increase the number of Celery tasks by two orders of magnitude.
Monkey patch everything!
One wrinkle in adopting Gevent is that not all of our I/O libraries could release the execution context to be taken up by another part of the code. The creators of Gevent came up with a clever solution for this problem.
Gevent includes Gevent-aware versions of the most common I/O low level libraries, such as socket, and offers a method to make the other existing libraries use the Gevent ones. As indicated by the code sample below, this method is referred to as monkey patching. While this method might seem like a hack, it has been used in production by large tech companies, including Pinterest and Lyft.
> from gevent import monkey
> monkey.patch_all()Adding the two lines above at the beginning of the application’s code makes Gevent automatically overwrite all the subsequent imported modules and use Gevent’s I/O libraries instead.
Implementing Gevent on our POS system
Instead of directly introducing the Gevent changes in the existing POS service, we created a new parallel application that had the patches related to Gevent, and gradually diverted traffic to it. This implementation strategy gave us the ability to switch back to the old non-Gevent application if anything went wrong.
Implementing the new Gevent application required the following changes:
Step 1: Install the following Python package
pip install geventStep 2: Monkey patch Celery
The non-Gevent application had the following code, in the celery.py file, to start up Celery:
from celery import Celery
from app import rabbitmq_url
main_app = Celery('app', broker=rabbitmq_url)
@app.task
def hello():
return 'hello world'The Gevent application included the below file, gcelery.py, along with the celery.py file.
from gevent import monkey
monkey.patch_all(httplib=False)
import app.celery
from app.celery import main_appWe used the code monkey.patch_all(httplib=False) to carefully patch all the portions of the libraries with Gevent-friendly functions that behave the same way as the original functions. This patching is performed early in the lifecycle of the application, before the Celery startup, as shown in celery.py.
Step 3: Bootstrap the Celery worker.
The non-Gevent application bootstraps Celery worker as follows:
exec celery -A app worker --concurrency=3 --loglevel=info --without-mingle The Gevent application bootstraps Celery worker as follows:
exec celery -A app.gcelery worker --concurrency=200 --pool gevent --loglevel=info --without-mingleThe following things changed when we implemented the Gevent application:
- The -
Acommand line argument determines the application to be run. - In the non-Gevent application, we directly bootstrap
celery.py. - In the Gevent application,
app.gceleryis run. Thegcelery.pyfile first monkey patches all the underlying libraries before calling the applicationcelery.py.
The -- concurrency command line argument determines the number of processes/threads. In the non-Gevent application, we have spawned only three processes. In the Gevent application, we have spawned only two hundred green threads.
The -- pool command line allows us to choose between processes or threads. In the Gevent application, we select Gevent since our tasks are more I/O bound.
Results
After rolling out the new POS application that used Gevent in production, we obtained excellent results. First of all, we were able to reduce our Kubernetes pods by a factor of 10, in turn reducing the amount of CPU we utilized by 90%. Despite this reduction, our order processing capacity increased by 600%.
Additionally, the CPU utilization of each pod went from less than 5% to roughly 30%.
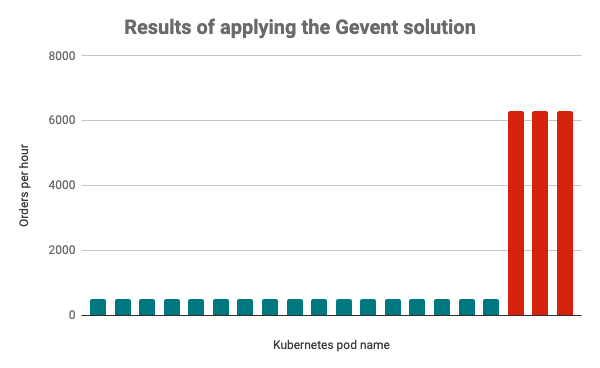
Our new system could also handle a much higher rate of requests, since we significantly reduced the number of outages due to misbehaving merchant APIs eating up most of our Celery tasks.
Conclusions
Gevent helped DoorDash improve the scalability and reliability of our services. It also enabled DoorDash to efficiently use resources during I/O operations by using event-based, asynchronous I/O thus reducing our resource usage.
Many companies develop Python-based microservices that are synchronous during I/O operations with other services, databases, caches, and message brokers. These companies can have a similar opportunity as DoorDash in improving scalability, reliability, and efficiency of their services by making use of this solution.