

Asynchronous task management using Gevent improves scalability and resource efficiency for distributed systems. However, using this tool with Kafka can be challenging.
At DoorDash, many services are Python-based, including the technologies RabbitMQ and Celery, which were central to our platform’s asynchronous task-queue system. We also leverage Gevent, a coroutine-based concurrency library, to further improve the efficiency of our asynchronous task processing operations. As DoorDash continues to grow, we have faced scalability challenges and encountered incidents that propelled us to replace RabbitMQ and Celery with Apache Kafka, an open source distributed event streaming platform offering superior reliability and scalability.
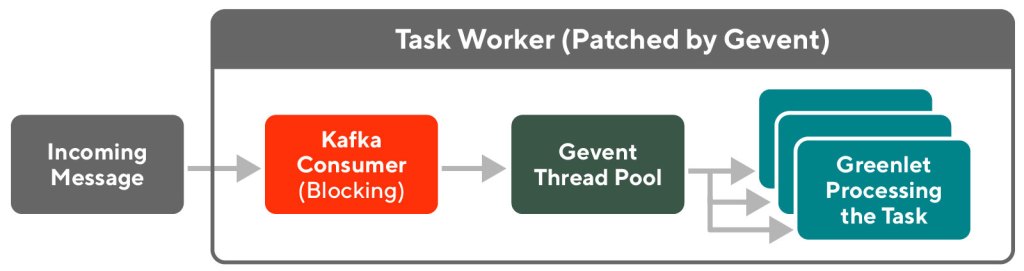
However when migrating to Kafka, we discovered that Gevent, the tool we use for asynchronous task processing in our point of sale (POS) system, is not compatible with Kafka. This incompatibility occurs because we use Gevent to patch our Python code libraries to perform asynchronous I/O, while Kafka is based on librdkafka, a C library. The Kafka consumer blocks the I/O from the C library and could not be patched by Gevent in the asynchronous way we are looking for.
We resolved this incompatibility issue by manually allocating Gevent to a greenlet thread, running Kafka consumer task processing inside the Gevent thread, and replacing the consumer task blocking I/O with Gevent’s version of the “blocking” call to achieve asynchronicity. Performance tests and actual production results have shown our Kafka consumer running smoothly with Gevent, and outperforming the Celery/Gevent task worker we had before, especially when dealing with heavy I/O time, which made downstream services slow.
Why move away from RabbitMQ/Celery to Kafka with Gevent?
In order to prevent a series of outages stemming from our task processing logic, several DoorDash engineering teams migrated from RabbitMQ and Celery to a custom Kafka solution. While the details can be found in this article, here is a brief summary of the advantages of moving to Kafka:
- Kafka is a distributed event streaming platform that is highly reliable and available. It is also famous for its horizontal scalability and handling of production data at massive scale.
- Kafka has great fault tolerance because data loss is avoided with partition replication.
- As Kafka is a distributed/pub-sub messaging system, its implementation fits into the broader move to microservices that has been rolled out at DoorDash.
- Compared to Celery, Kafka has better observability and operational efficiency, and has helped us address the issues and incidents we encountered when using Celery.
Since the migration to Kafka, many DoorDash teams have seen reliability and scalability improvements. In order to gain similar benefits, our merchant team prepared to migrate its POS service to Kafka. Complicating this migration is the fact that our team’s services also utilize Gevent, because:
- Gevent is a coroutine and non-blocking I/O based Python library. With Gevent we can process heavy network I/O tasks asynchronously without them being blocked on waiting for I/O, while still writing code in a synchronous fashion. To learn more about our original implementation of Gevent, read this blog article.
- Gevent can easily monkey-patch existing application code or a third party library for asynchronous I/O, thus making it easy to use for our Python-based services.
- Gevent has lightweight execution via greenlets, and performs well when scaling with the application.
- Our services have heavy network I/O operations with external parties like merchants, whose APIs may have long and spiky latency, which we don’t control. Thus we need asynchronous task processing to improve resource utilization and service efficiency.
- Before implementing Gevent, we used to suffer when a major partner was having an outage, which could impact our own service performance.
As Gevent is a critical component for helping us achieve high task processing throughput, we wanted to gain the advantages from migrating to Kafka and keep the benefits of using Gevent.
The new challenges of migrating to Kafka
When we started migrating from Celery to Kafka, we faced new challenges when trying to keep Gevent intact. First, we wanted to maintain the existing task processing high throughput that was enabled by Gevent, but we could not find an out-of-the box Kafka Gevent library, or any online resources for combining Kafka and Gevent.
We studied how DoorDash’s monolith application migrated from Celery to Kafka, and found those use cases were using a dedicated process per each task. In our services and with our use cases, dedicating a process per task would cause excessive resource consumption compared to utilizing the Gevent threads. We simply couldn’t replicate the migration work that had been done before at DoorDash, and had to work out a newer implementation for our use cases, which involved operating with Gevent without the loss of efficiency.
When we looked into our own Kafka consumer implementation with Gevent, we identified an incompatibility problem: as the confluent-kafka-python library we use is based on the C library librdkafka, its blocking calls cannot be monkey-patched by Gevent because Gevent only works on Python code and libraries. If we naively replace the Celery worker with a Kafka consumer to poll task messages, our existing task processing Gevent threads will be blocked by the Kafka consumer polling call, and we will lose all the benefits of using Gevent.
while True:
message = consumer.poll(timeout=TIME_OUT)
if not message:
continueFigure 2: This code snippet is a typical Kafka consumer implementation with a defined timeout on message polling. However, it blocks Gevent threads as timeout is performed by librdkafka.
Replacing Kafka’s blocking call with a Gevent asynchronous call
By studying online articles about a similar problem when working with Kafka producer and Gevent, we came up with a solution for solving the incompatibility issue between the Kafka consumer and Gevent: when the Kafka consumer polls messages, we set the Kafka blocking timeout to zero, which no longer blocks our Gevent threads.
In the case where there’s no message available to poll, in order to save the CPU cycle in the message polling loop, we add a gevent.sleep(timeout) call. In this way, we can context switch to perform other threads’ work while the Kafka consumer thread is in sleep. Because the sleep is performed by Gevent, other Gevent threads will not be blocked while we wait for the next consumer message poll.
while True:
message = consumer.poll(timeout=0)
if not message:
gevent.sleep(TIME_OUT)
continueFigure 3: Setting the Kafka consumer message polling timeout to zero no longer blocks Gevent threads.
A possible tradeoff for doing this manual Gevent thread context switching is that if we interfere with the Kafka message consuming cycle, we may sacrifice any optimizations that come from the Kafka library. However, through performance testing, we haven’t seen degradations after making those kinds of changes, and could actually see performance improvements using Kafka compared to Celery.
Throughput comparison: Kafka vs Celery
The chart below displays the throughput comparison, in execution time between Kafka and Celery. Celery and Kafka show similar results on small loads, but Celery is relatively sensitive to the amount of the concurrent jobs that it runs, while Kafka keeps processing time almost the same regardless of the load. The maximum number of jobs that were run concurrently in the tests is 6,000 and Kafka shows great throughput even with I/O delays in the jobs, while Celery task execution time increases noticeably up to 140 seconds. While Celery is competitive for small amounts of jobs with no I/O time, Kafka outperforms Celery for large amounts of concurrent jobs, especially when there are I/O delays.
| Parameters | Kafka execution time | Celery execution time |
| 100 jobs per request, 5 requests no I/O timeout | 256 ms | 153 ms |
| 200 jobs per request, 5 requests no I/O timeout | 222 ms | 257 ms |
| 200 jobs per request, 10 requests no I/O timeout | 251 - 263 ms | 400 ms - 2 secs |
| 200 jobs per request, 20 requests no I/O timeout | 255 ms | 650 ms |
| 300 jobs per request, 10 requests no I/O timeout | 256 - 261 ms | 443 ms |
| 300 jobs per request, 10 requests 5 secs I/O timeout | 5.3 secs | 10 - 61 secs |
| 300 jobs per request, 20 requests 5 secs I/O timeout | 5.25 secs | 10 - 140 secs |
Results
Migrating from Celery to Kafka while still using Gevent allows us to have a more reliable task queuing solution while maintaining high throughput. Performance experiments above show promising results for high volume and high I/O latency situations. So far we have been running Kafka consumer with Gevent for a couple of months in production, and have seen reliably high throughput without the recurrence of issues we saw before when we used Celery.
Conclusion
Using Kafka with Gevent is a powerful combination. Kafka has proven itself and gained popularity as a messaging bus and queueing solution, while Gevent is a powerful tool to improve I/O heavy Python service throughput. Unfortunately, we couldn’t find any library available for combining Kafka and Gevent together, possibly due to the reason that Gevent doesn’t work with the C library librdkafka on which Kafka is based. For our case, we went through the struggle, but were happy to find a working solution to mix the two. For other companies, if high throughput, scalability, and reliability are the desired properties for their Python applications that require a messaging bus, Kafka with Gevent could be the answer.
Acknowledgments
The authors would like to thank Mansur Fattakhov, Hui Luan, Patrick Rogers, Simone Restelli, and Adi Sethupat for their contributions and advice during this project.